



Мощная новинка, которая появилась в Excel 365 в конце 2023 года: функции, которые позволяют агрегировать данные, де-факто — строить сводные таблицы, но формулами, то есть с автоматическим
обновлением. К тому же эти функции можно использовать как аргументы других функций (и им передавать в качестве аргументов не диапазоны, а другие функции), что еще мощнее расширяет возможности.
Как и многие другие функции, эти не могли появиться без динамических массивов — ведь одна функция здесь выдает результат больше одной ячейки (и он может измениться в любой момент при
изменении исходных данных).
обновлением. К тому же эти функции можно использовать как аргументы других функций (и им передавать в качестве аргументов не диапазоны, а другие функции), что еще мощнее расширяет возможности.
Как и многие другие функции, эти не могли появиться без динамических массивов — ведь одна функция здесь выдает результат больше одной ячейки (и он может измениться в любой момент при
изменении исходных данных).
ГРУПППО / GROUPBY позволяет группировать только в строках, а СВОДПО / PIVOTBY — и в столбцах тоже. Обязательных аргументов всего три (в случае с ГРУПППО) или четыре (в случае СВОДПО): по какому столбцу группируем в строках (и в столбцах, если используем СВОДПО), какой агрегируем, какую функцию (или вычисление, но об этом ниже) применяем.
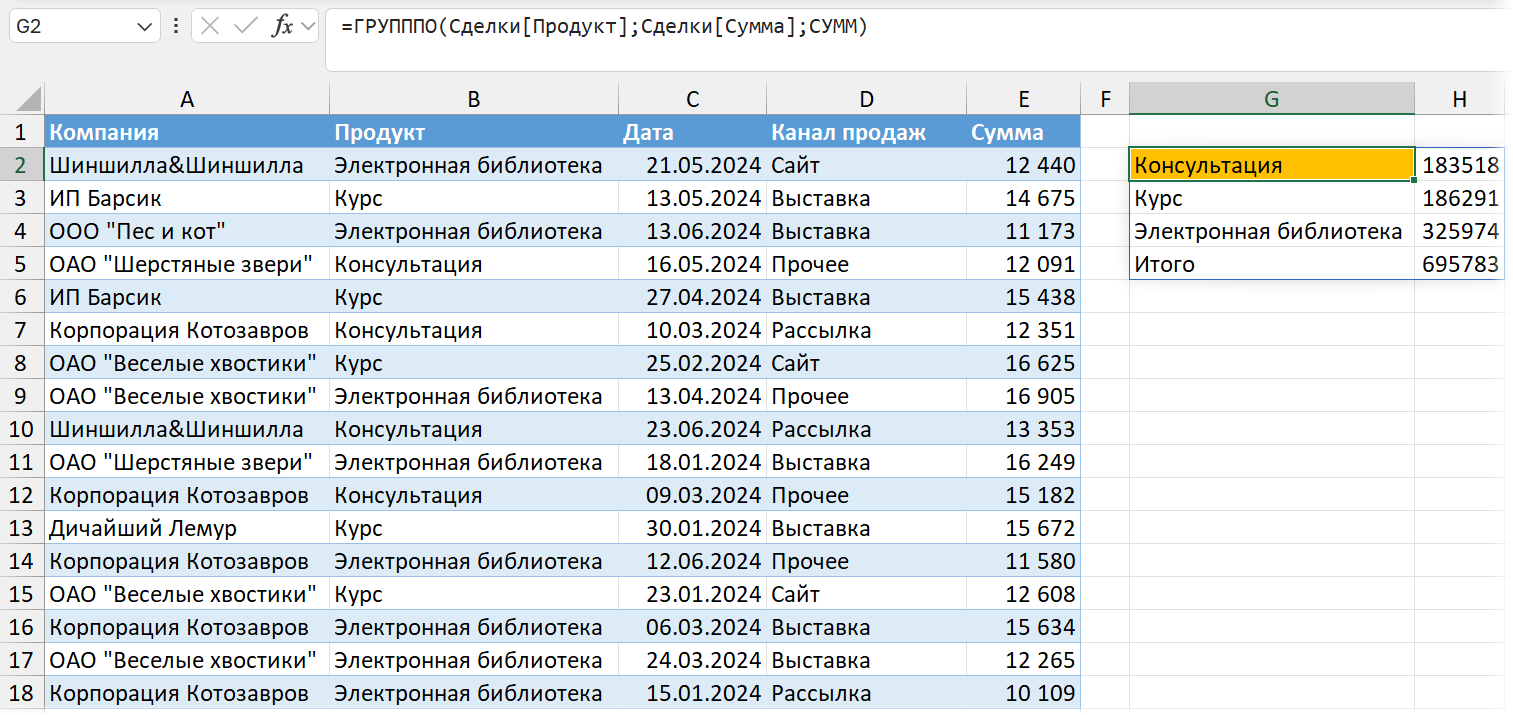
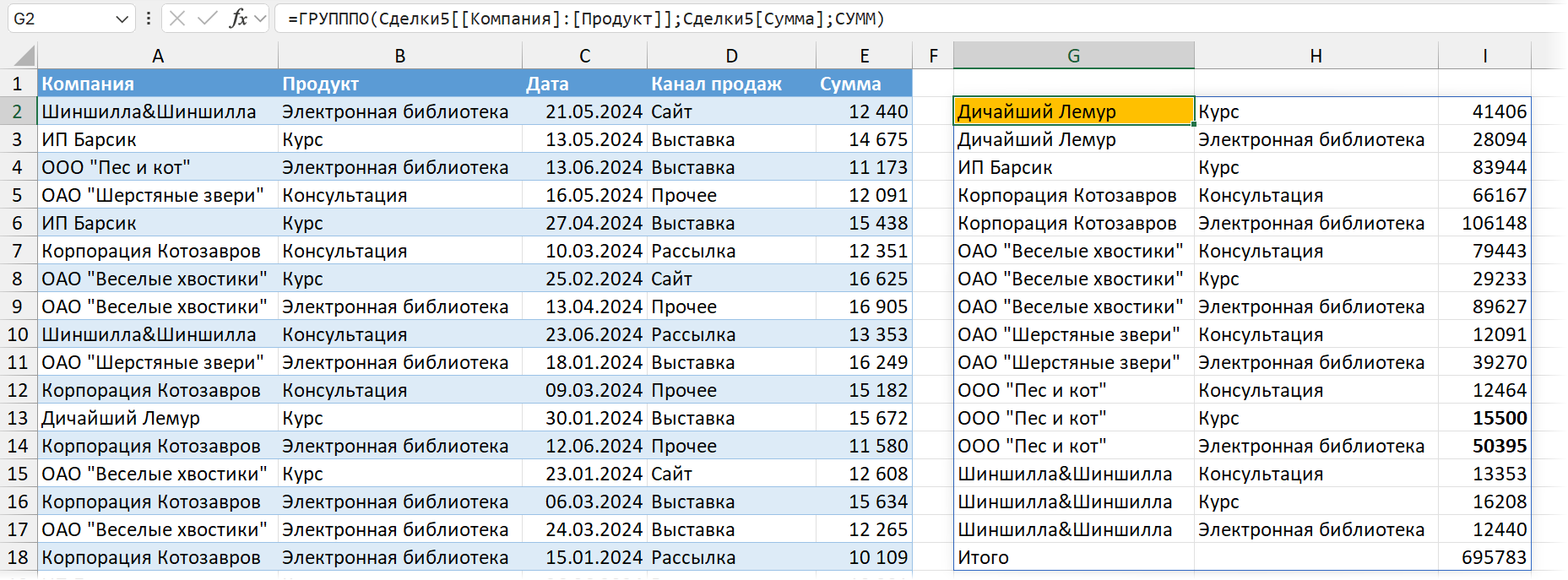
В следующем примере суммируем (в третьем аргументе указана функция СУММ) продажи из столбца «Сумма» в таблице «Сделки», группируя их по продуктам:
В следующем примере суммируем (в третьем аргументе указана функция СУММ) продажи из столбца «Сумма» в таблице «Сделки», группируя их по продуктам:
=ГРУПППО(Сделки[Продукт];Сделки[Сумма];СУММ)
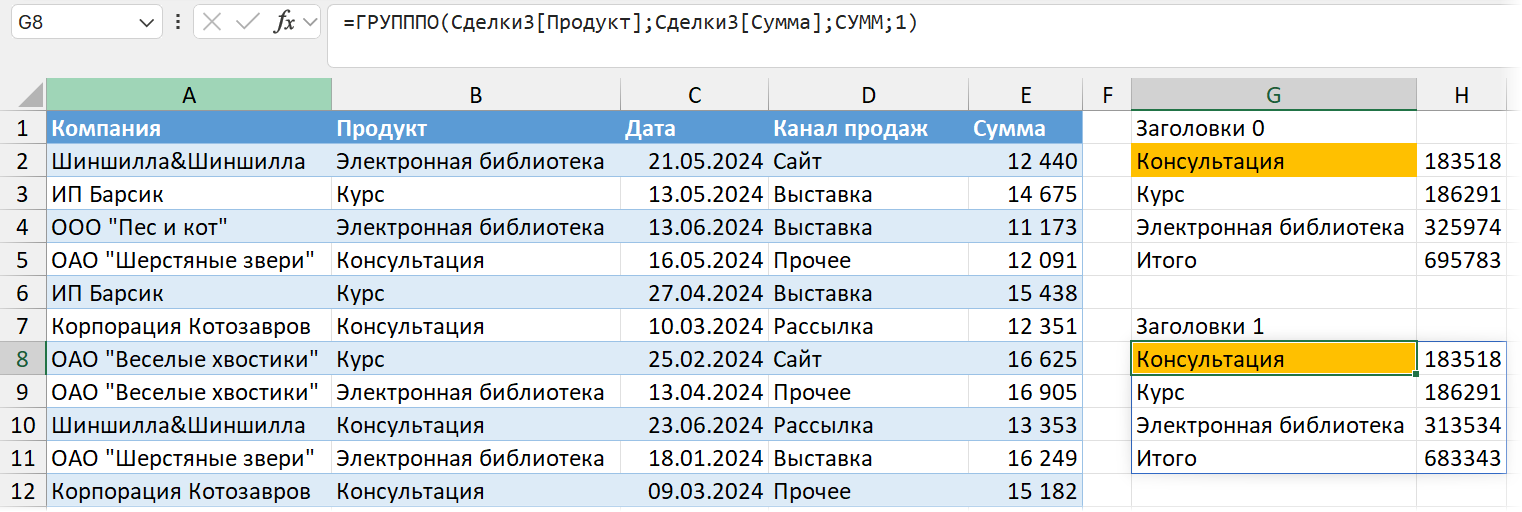
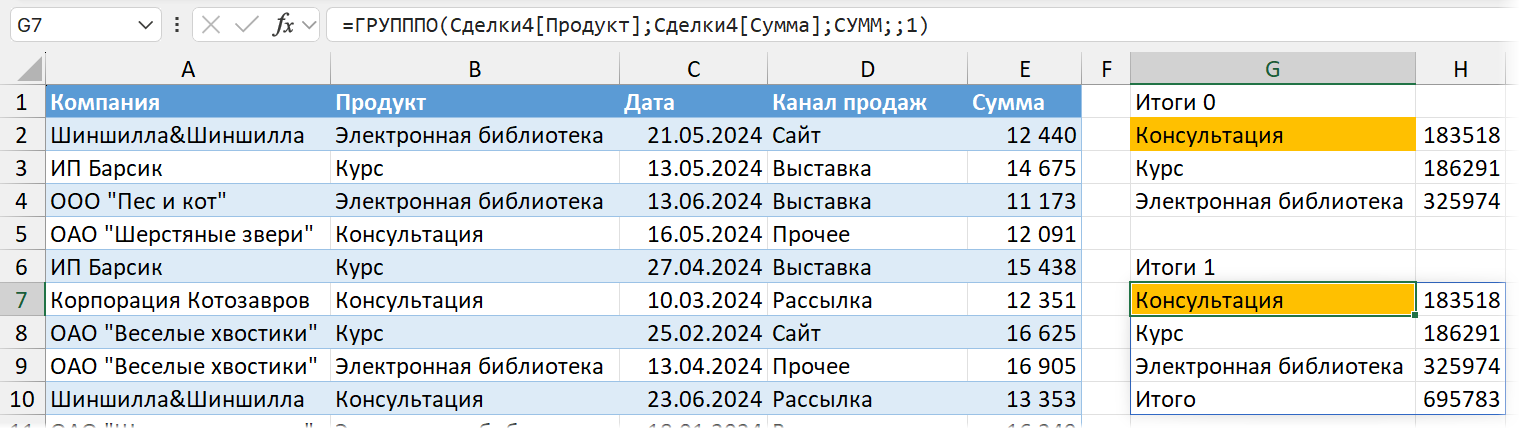
Четвертый аргумент — заголовки. По умолчанию 0 (ноль), заголовков нет. Как на скриншоте выше. 1 = да, заголовки есть в данных, но в сводноой показывать не надо. Этот вариант в нашем случае категорически не подходит: ведь мы ссылаемся на умную таблицу без заголовков, только на данные. И если применить аргумент 1, то первая строка данных будет считаться заголовком и в расчетах не отразится. Обратите внимание на итоговую сумму и сумму по библиотеке.
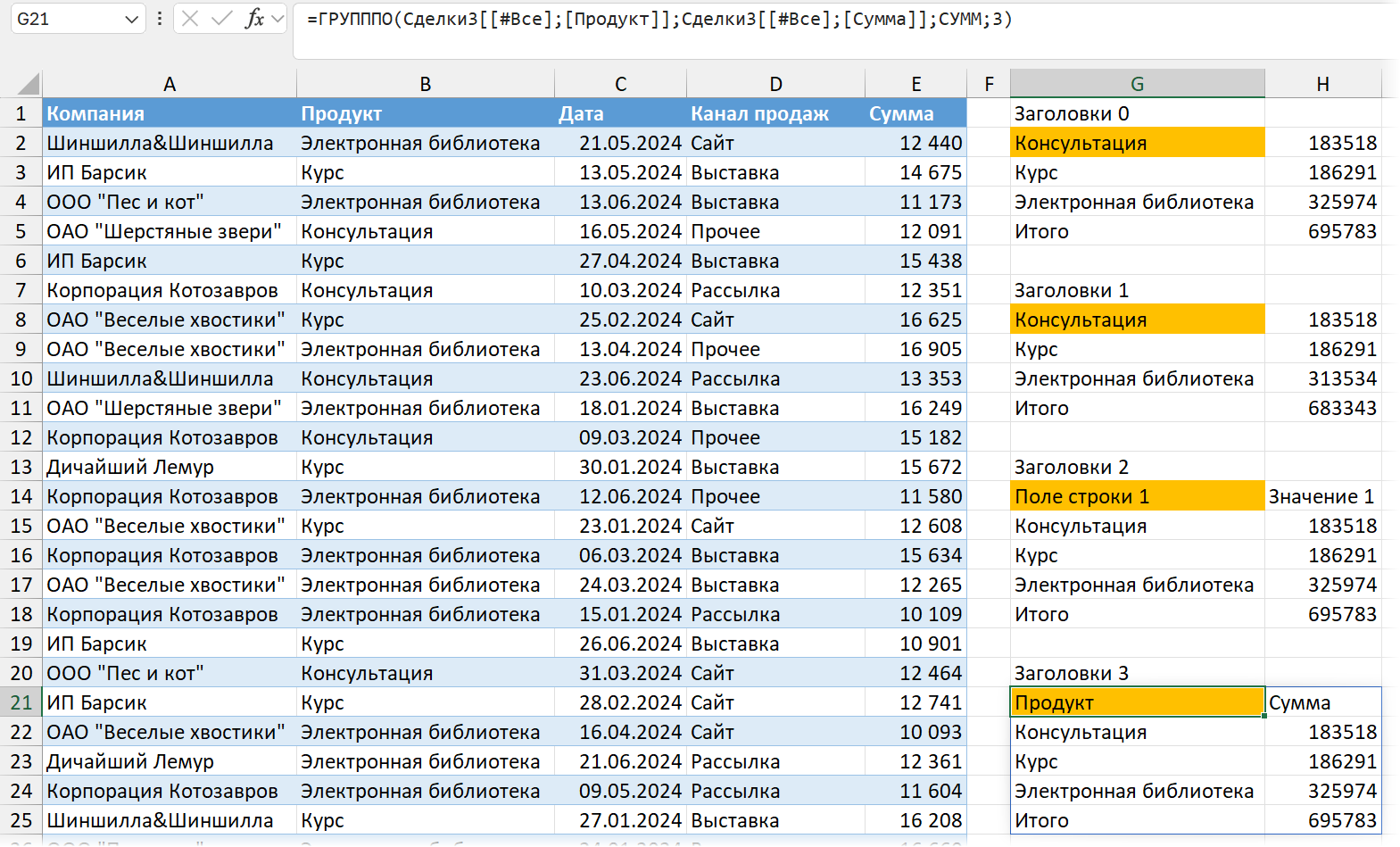
Другие варианты заголовков: 2 — заголовков нет в данных, но они создаются функцией. 3 — заголовки есть в данных и их нужно показать (если мы применяем такой вариант аргумента, то ссылаться надо на данные с заголовком, как на скриншоте ниже):
Итоги добавляются по умолчанию. Можно настроить их поведение с помощью аргумента total_depth (в ГРУПППО он пятый по порядку). 1 = вариант по умолчанию, итоги показываются.
Например, если он будет равен нулю — итогов не будет.
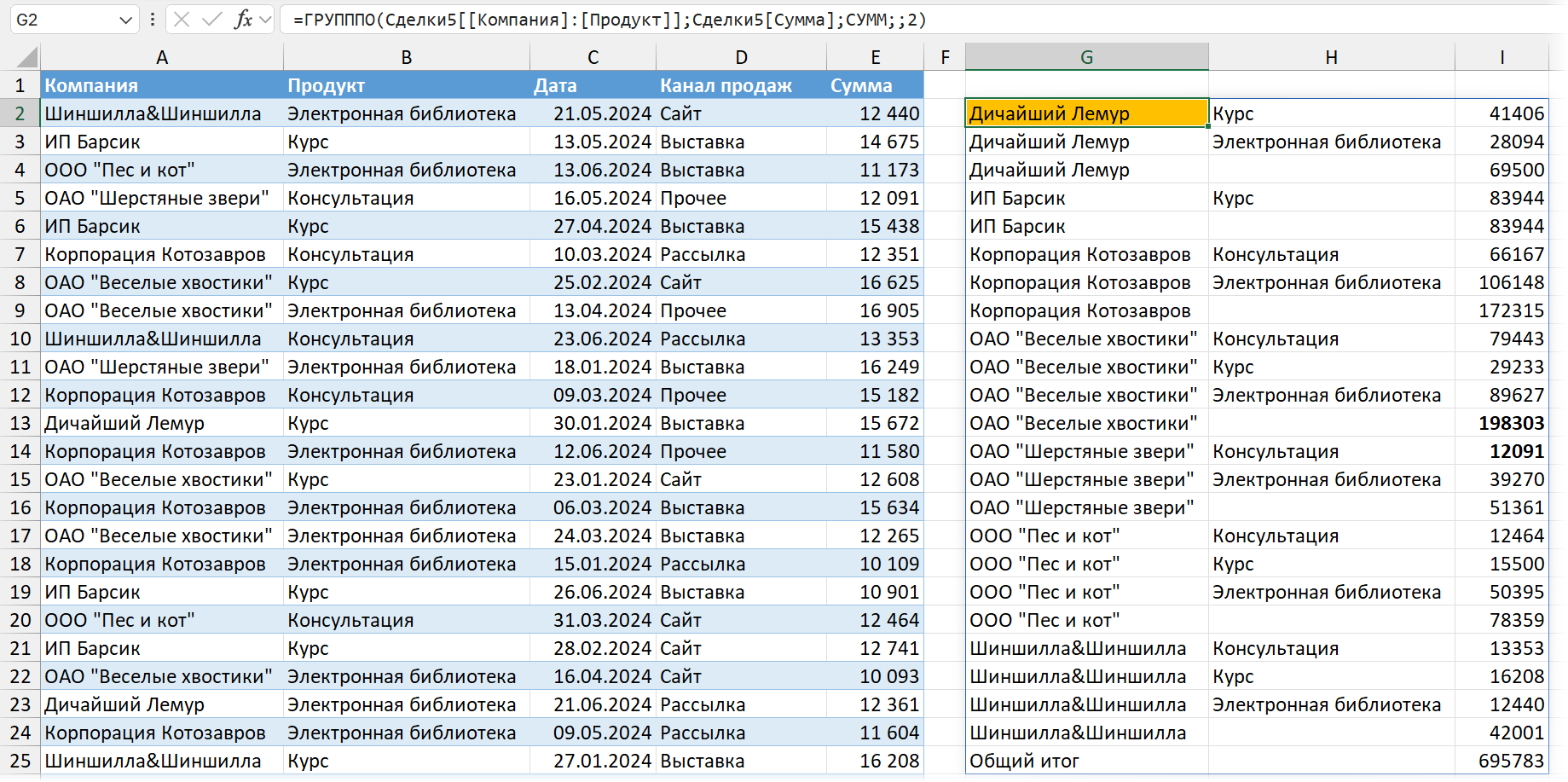
Уровней группировки может быть и несколько.
Тогда можно добавить и промежуточные итоги с помощью того же аргумента total_depth. 2 = общие и промежуточные, -2 (с минусом) = общие и промежуточные сверху.
Данные можно сортировать: для этого в аргументе sort_order задается номер столбца, по которому нужно сортировать. Если нужно сортировать по убывающей — то со знаком минус. Номер столбца указывается в рамках результата, а не исходной таблицы. То есть в нашем случае 1 будет соответствовать сортировке по компаниям, 2 — по продуктам по убыванию, 3 — по суммам. Так как у нас в таблице два уровня группировки, то сортировка происходит в рамках каждой компании, а не вообще:
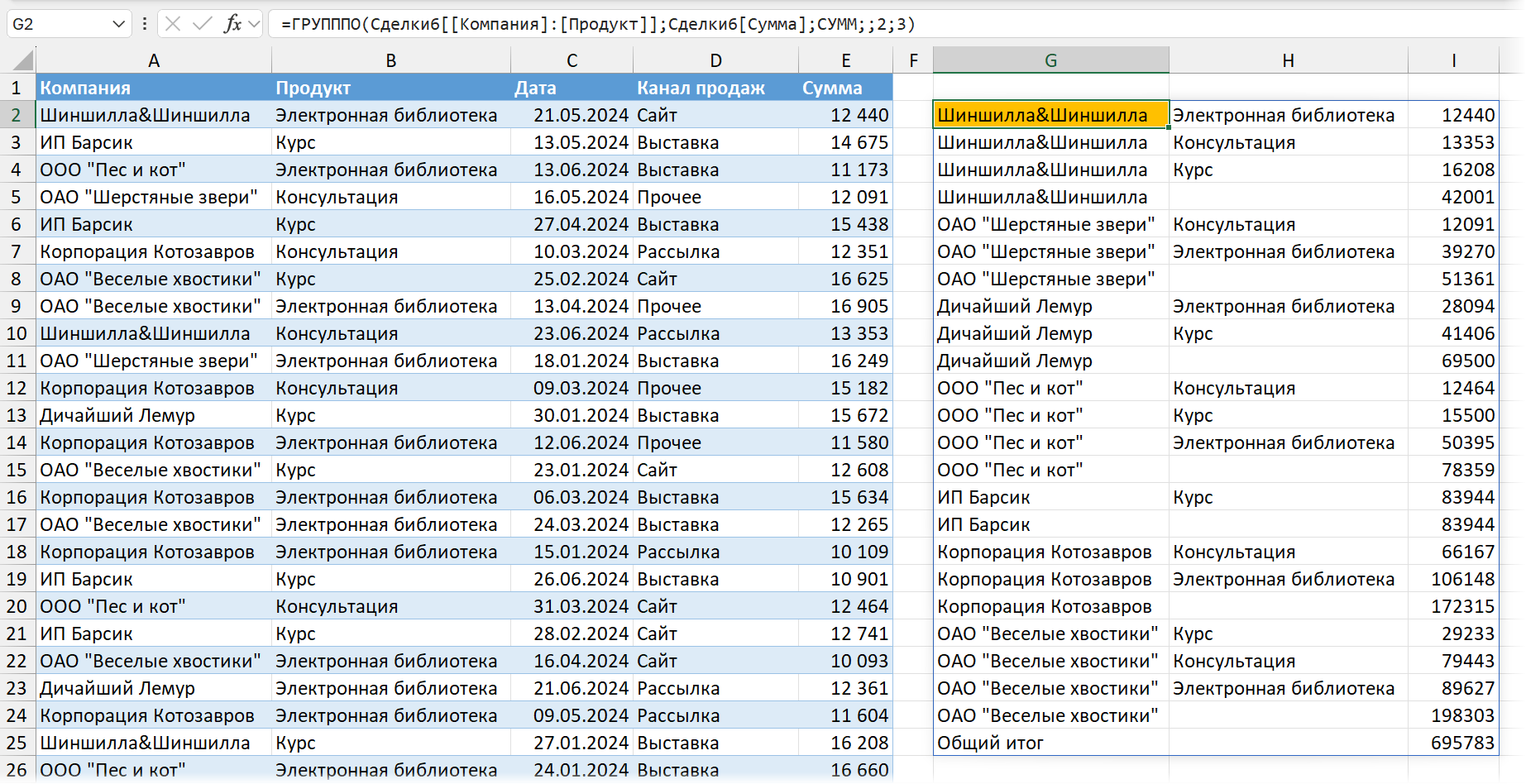
Тут в дело вступает последний аргумент функции — field_relationship, отношение полей. Его значение можно поменять на единице, но только если мы уберем промежуточные итоги. Тогда можно будет сортировать всю таблицу, каждую строку отдельно, а не в рамках компании.
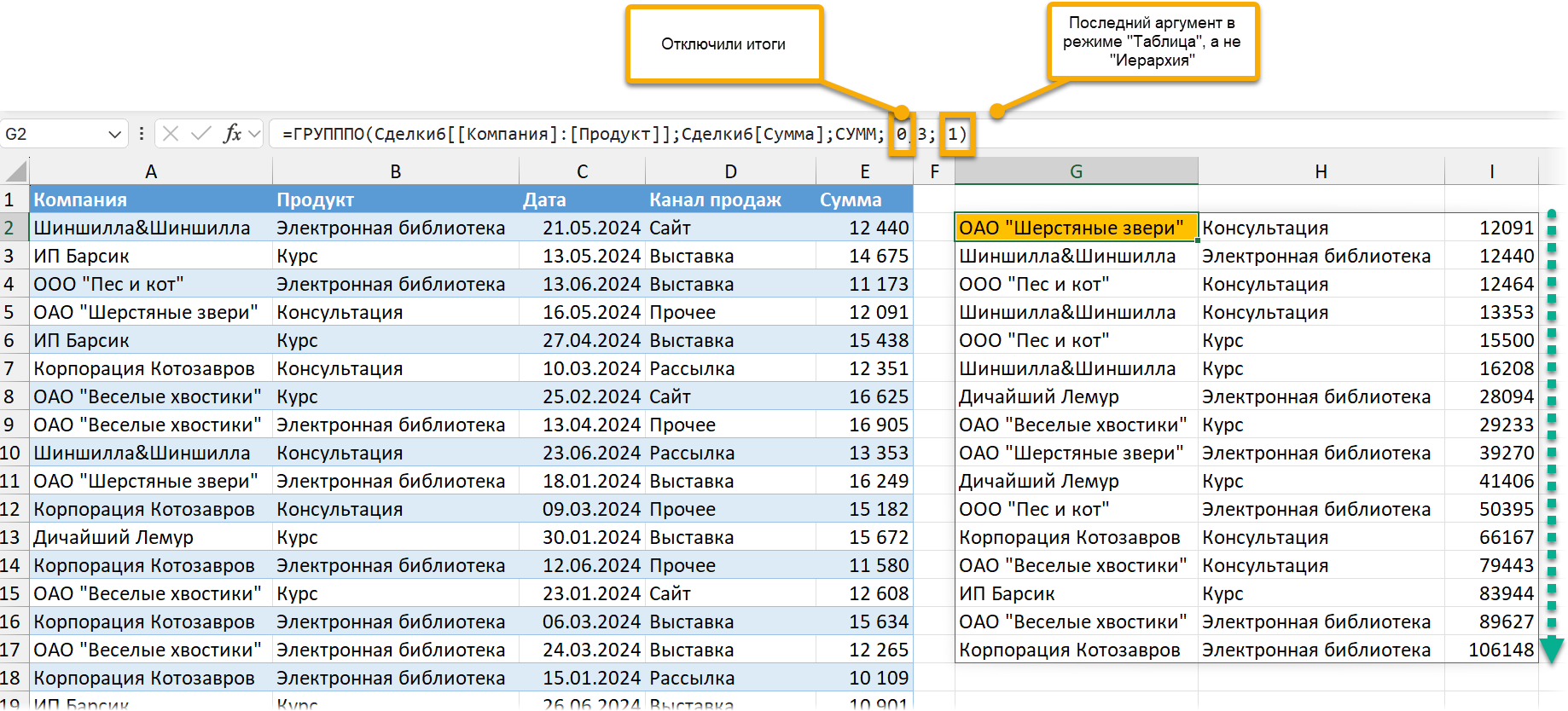
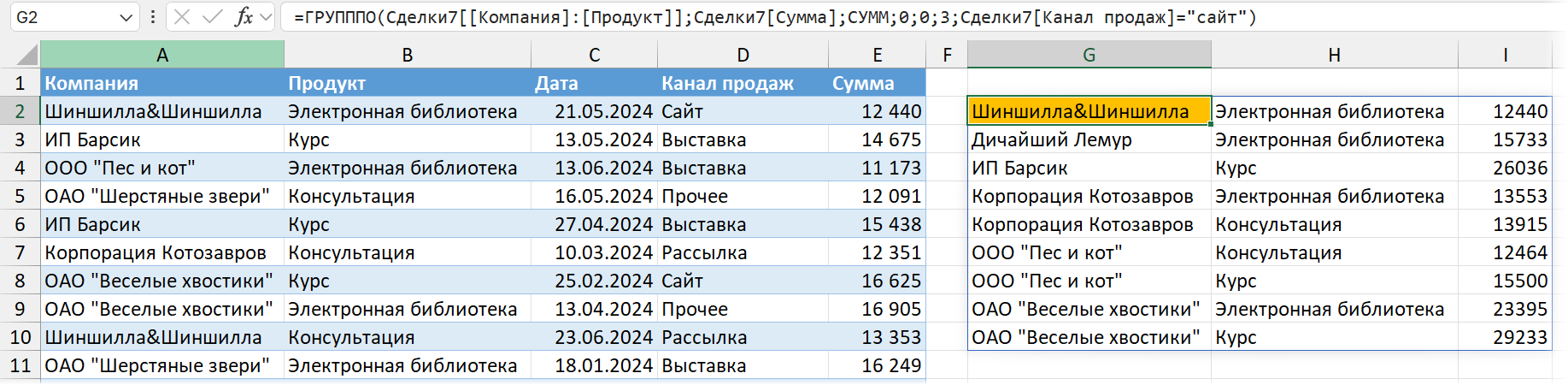
Фильтровать данные тоже можно. Для этого используется аргумент filter_array. В нем должно быть такое выражение, которое будет верным (выдаст ИСТИНА / TRUE) для тех строк, которые нужно оставить, и ЛОЖЬ / FALSE — для тех, которые не должны попасть в результат.
Например, если мы хотим фильтровать по одному каналу продаж (сайту), подойдет такое выражение:
Сделки[Канал продаж]="сайт"
Полностью функция будет выглядеть так:
=ГРУПППО(Сделки[[Компания]:[Продукт]];Сделки[Сумма];СУММ;0;0;3;Сделки[Канал продаж]="сайт")
Например, если мы хотим фильтровать по одному каналу продаж (сайту), подойдет такое выражение:
Сделки[Канал продаж]="сайт"
Полностью функция будет выглядеть так:
=ГРУПППО(Сделки[[Компания]:[Продукт]];Сделки[Сумма];СУММ;0;0;3;Сделки[Канал продаж]="сайт")
Если мы хотим группировать и по столбцам, то нужно использовать СВОДПО / PIVOTBY. Функция отличается наличием второго аргумента, в котором указывается поле (или поля) для группировки
в столбце. В следующем примере это поле «Компании».
=СВОДПО(Сделки[Продукт];Сделки[Компания];Сделки[Сумма];ПРОЦЕНТ)
в столбце. В следующем примере это поле «Компании».
=СВОДПО(Сделки[Продукт];Сделки[Компания];Сделки[Сумма];ПРОЦЕНТ)

Обратите внимание, что здесь применяется вычисление ПРОЦЕНТ, — и поэтому отображаются доли, а не суммы. Увы, значения автоматически не форматируются как проценты — мы можем либо отформатировать ячейки вручную, либо добавить функцию ТЕКСТ / TEXT сверху с нужным форматом:
=ТЕКСТ(СВОДПО(Сделки[Продукт];Сделки[Компания]; Сделки[Сумма];ПРОЦЕНТ);"0%")
=ТЕКСТ(СВОДПО(Сделки[Продукт];Сделки[Компания]; Сделки[Сумма];ПРОЦЕНТ);"0%")

И тут давайте задумаемся — а что вообще такое СУММ или ПРОЦЕНТ в третьем аргументе функции ГРУПППО или четвертом аргументе СВОДПО?
А это на самом деле короткая запись LAMBDA, без аргументов. В такой форме пропускается аргумент, если с ним ничего дополнительно не происходит, иначе говоря, запись
ПРОЦЕНТ
эквивалентна записи
LAMBDA(x; ПРОЦЕНТ (x))
x — это лишь название переменной, того, что мы даем "на вход". Оно может быть и другим, важно другое: если мы ничего не делаем с тем, что получаем на входе, а только применяем функцию, то мы можем вообще не задавать для этого самого входа название переменной, а просто сказать:
ПРОЦЕНТ или СУММ
Как мы делали выше в случае с функциями ГРУПППО и СВОДПО.
Но раз в них возможна короткая запись LAMBDA, значит, возможна и обычная, когда мы делаем с данными что-то большее, чем просто применяем одну из базовых функций вроде СУММ?
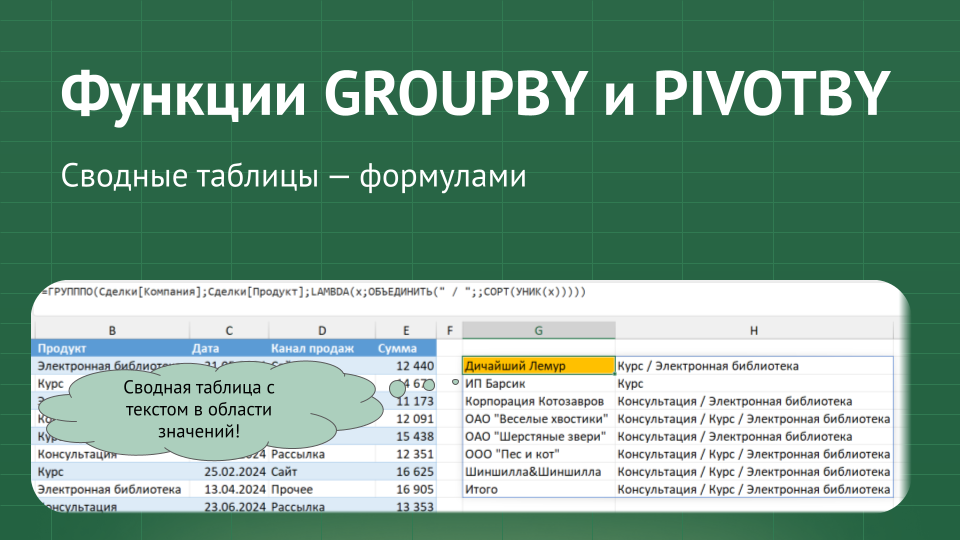
Да! Мы можем производить с данными в нашей "сводной", сформированной функциями ГРУПППО и СВОДПО, самые разные вычисления. Например, мы можем сделать сводную таблицу с текстом в области значений — показать названия продуктов, которые покупает каждый из наших клиентов.
Сначала давайте разберемся, что вообще здесь будет "иксом" (или другим названием переменной, которую мы отдадим в LAMBDA)? Это значения из исходной таблицы по тому столбцу, который мы отправляем в "область значений" (если проводить аналогии с классической сводной таблицей) — во второй аргумент функции ГРУПППО "values". Можно наглядно это увидеть, если применить функцию МАССИВВТЕКСТ, которая просто отобразит данные через разделитель (точку с запятой):
А это на самом деле короткая запись LAMBDA, без аргументов. В такой форме пропускается аргумент, если с ним ничего дополнительно не происходит, иначе говоря, запись
ПРОЦЕНТ
эквивалентна записи
LAMBDA(x; ПРОЦЕНТ (x))
x — это лишь название переменной, того, что мы даем "на вход". Оно может быть и другим, важно другое: если мы ничего не делаем с тем, что получаем на входе, а только применяем функцию, то мы можем вообще не задавать для этого самого входа название переменной, а просто сказать:
ПРОЦЕНТ или СУММ
Как мы делали выше в случае с функциями ГРУПППО и СВОДПО.
Но раз в них возможна короткая запись LAMBDA, значит, возможна и обычная, когда мы делаем с данными что-то большее, чем просто применяем одну из базовых функций вроде СУММ?
Да! Мы можем производить с данными в нашей "сводной", сформированной функциями ГРУПППО и СВОДПО, самые разные вычисления. Например, мы можем сделать сводную таблицу с текстом в области значений — показать названия продуктов, которые покупает каждый из наших клиентов.
Сначала давайте разберемся, что вообще здесь будет "иксом" (или другим названием переменной, которую мы отдадим в LAMBDA)? Это значения из исходной таблицы по тому столбцу, который мы отправляем в "область значений" (если проводить аналогии с классической сводной таблицей) — во второй аргумент функции ГРУПППО "values". Можно наглядно это увидеть, если применить функцию МАССИВВТЕКСТ, которая просто отобразит данные через разделитель (точку с запятой):
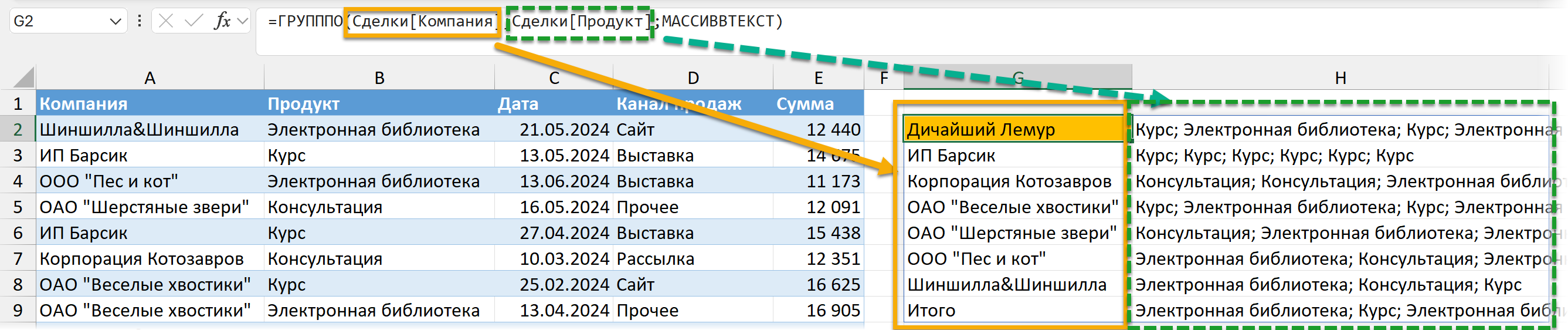
То есть мы получили все значения из столбца "Продукт" для каждого клиента — видим, например, что ИП Барсик покупал только курс, но покупал шесть раз. А нам не нужно 6 раз — мы хотим показать каждое значение один раз. Как это сделать? Удалить дубликаты в списке с помощью функции УНИК / UNIQUE. Если бы мы применяли ее к исходному столбцу, мы бы получили список уникальных продуктов вообще. А если мы применим ее в рамках той группировки, которую задали в функции ГРУПППО (по клиентам) — то и уникальные значения получим в рамках этой группировки (для каждого клиента).
Но если просто применить УНИК, чуда не случится — будет ошибка:
=ГРУПППО(Сделки[Компания];Сделки[Продукт]; LAMBDA(x; УНИК(x)))
Но если просто применить УНИК, чуда не случится — будет ошибка:
=ГРУПППО(Сделки[Компания];Сделки[Продукт]; LAMBDA(x; УНИК(x)))
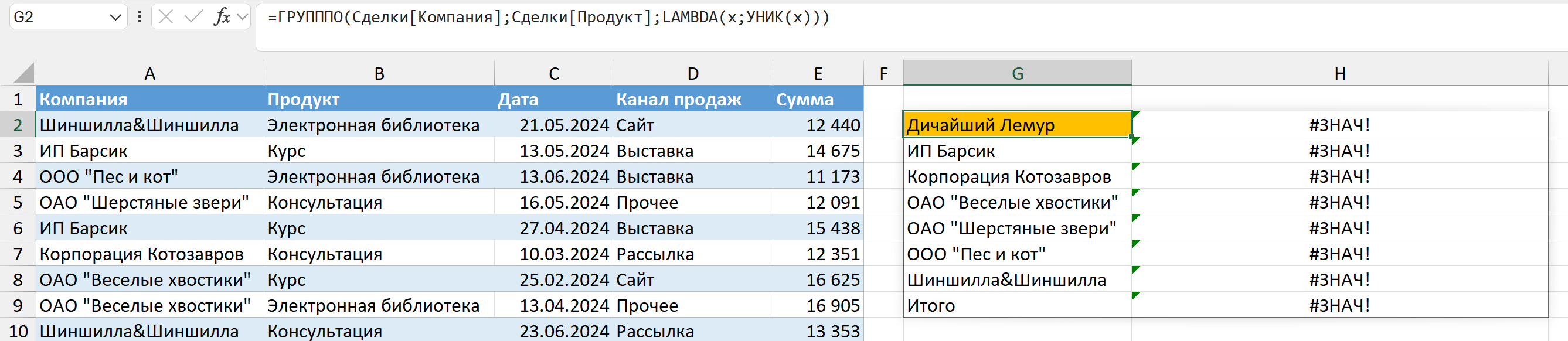
Потому что УНИК возвращает массив, а здесь возвращение массива не предполагается, нам надо сжать данные в одну ячейку этой "сводной". Это можно сделать как раз с помощью МАССИВВТЕКСТ:
=ГРУПППО(...; LAMBDA(x; МАССИВВТЕКСТ(УНИК(x))))
=ГРУПППО(...; LAMBDA(x; МАССИВВТЕКСТ(УНИК(x))))
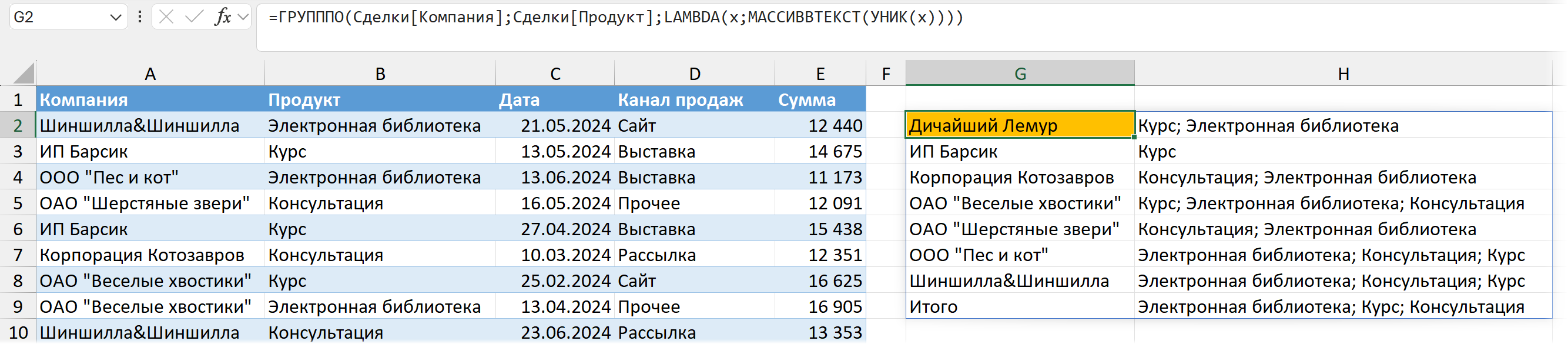
Напрашивается сортировка — одинаковая для всех клиентов. Чтобы "Курс" был у всех на одинаковой позиции, если он есть — по алфавиту; а не там, где он окажется у каждого клиента, исходя из того, в каком порядке у этого клиента идут сделки. Нам никто не мешает для этого добавить сортировку с помощью функции СОРТ:
=ГРУПППО(...; LAMBDA(x; МАССИВВТЕКСТ(СОРТ(УНИК(x)))))
=ГРУПППО(...; LAMBDA(x; МАССИВВТЕКСТ(СОРТ(УНИК(x)))))
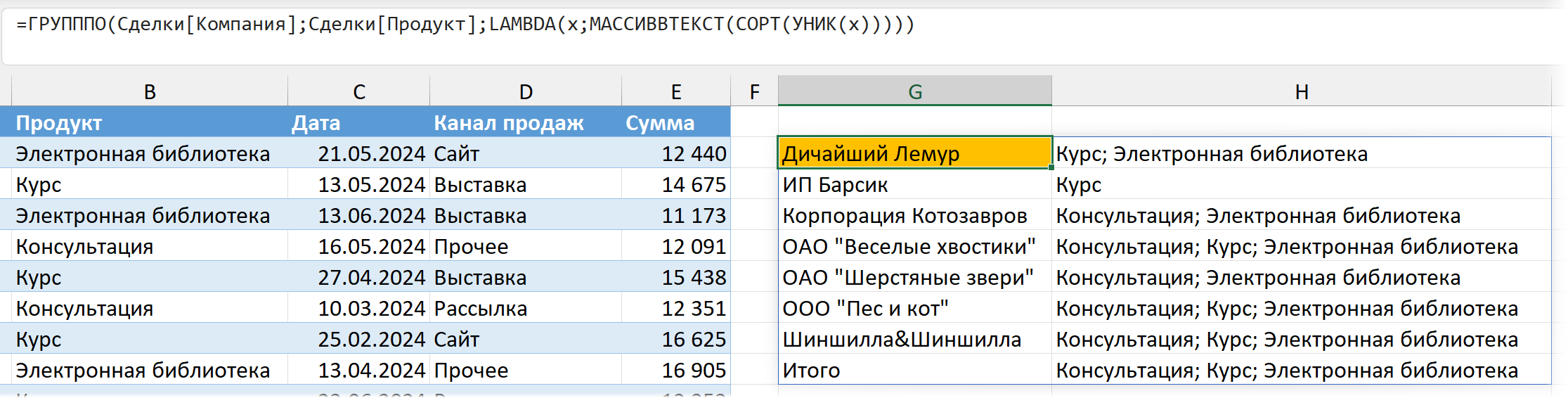
А если хотим другой разделитель — не точку с запятой? А, например, просто запятую или вертикальную черту? Тогда заменим МАССИВВТЕКСТ на функцию ОБЪЕДИНИТЬ (TEXTJOIN) — в ней можно задать любой разделитель. Запятую, вертикальную черту, косую черту с пробелами или что угодно еще:
=ГРУПППО(... ;LAMBDA(x; ОБЪЕДИНИТЬ(" / " ; ; СОРТ(УНИК(x)))))
=ГРУПППО(... ;LAMBDA(x; ОБЪЕДИНИТЬ(" / " ; ; СОРТ(УНИК(x)))))
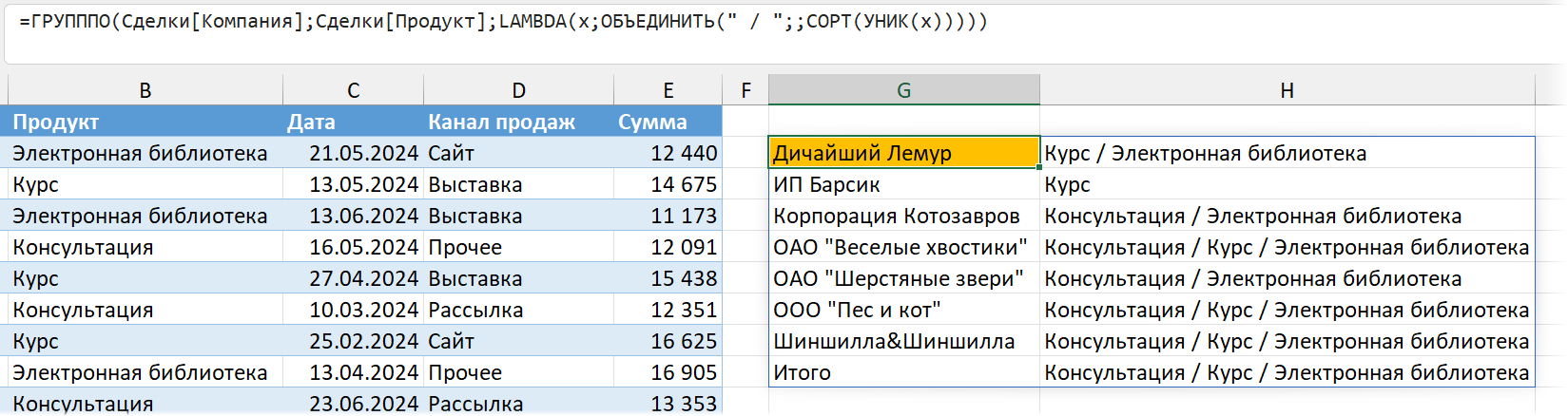
(второй аргумент функции ОБЪЕДИНИТЬ пустой — это пропуск пустых ячеек, которых тут не предвидится, так что нам не важно, будет ли этот аргумент равен ИСТИНА или ЛОЖЬ, мы оставляем его пустым, что эквивалентно ИСТИНЕ — пропускать)
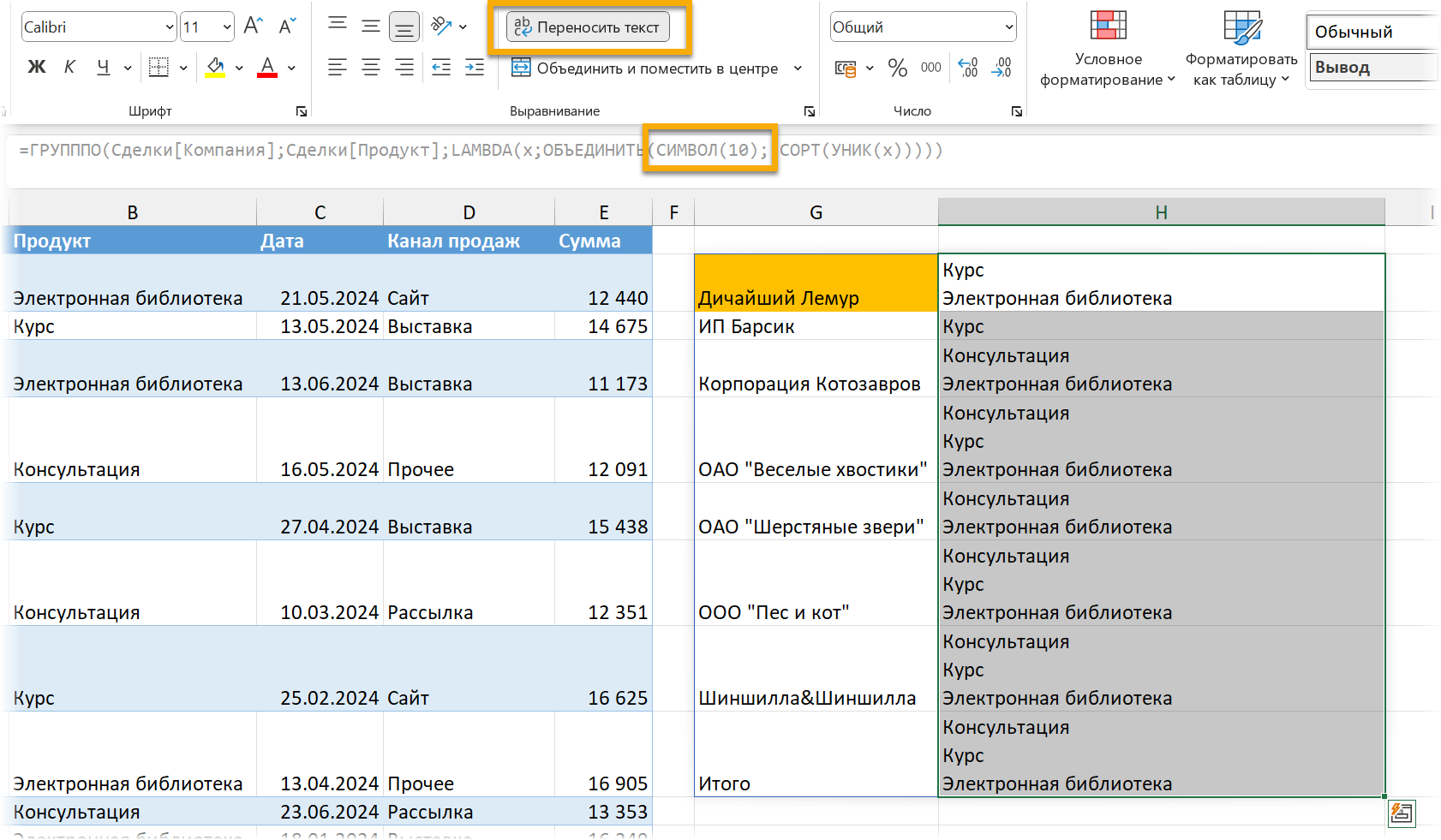
Еще один интересный вариант разделителя — перенос строки. Его нельзя ввести напрямую, но можно с помощью функции СИМВОЛ / CHAR с кодом 10. Только тогда у ячеек нужно будет включить перенос текста:
Еще один интересный вариант разделителя — перенос строки. Его нельзя ввести напрямую, но можно с помощью функции СИМВОЛ / CHAR с кодом 10. Только тогда у ячеек нужно будет включить перенос текста:
Про эти и многие другие новые функции еще больше — в моем новом курсе "Магия новых функций Excel. Массивы, регулярные выражения и многое другое".




