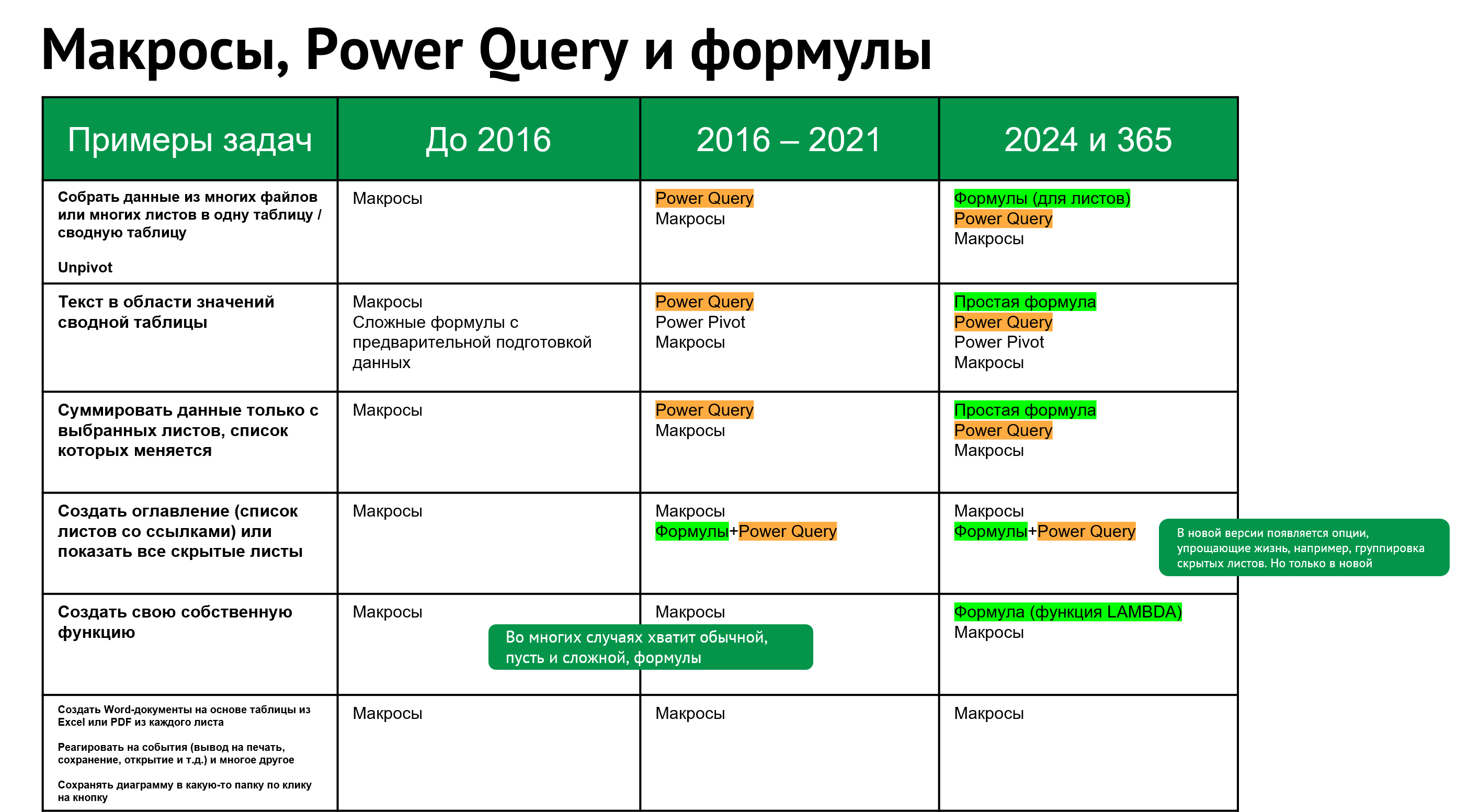
Появление функции LAMBDA — это прямо-таки революция в табличных формулах. Теперь можно создавать свои собственные функции. Да, это можно было делать и раньше, но для этого нужно было залезать в Visual Basic и программировать. А теперь все в рамках привычного рабочего листа.
К тому же LAMBDA — это не только для того, чтобы создавать свои функции и потом использовать, не вводя их с нуля. LAMBDA позволяет написать функцию, которая будет применяться к каждому элементу массива (для этого понадобится вспомогательная функция MAP), к каждому элементу массива и еще к накопленному итогу на каждом шаге (SCAN и REDUCE), к каждой строке или столбцу (BYROW и BYCOL), к каждому элементу формируемого массива (с возможностью обращения к индексу его строки и столбца - MAKEARRAY)
А еще — только в Excel (не в Google Таблицах) — можно использовать LAMBDA внутри других новых функций ГРУПППО / GROUPBY и СВОДПО / PIVOTBY для формирования «сводных таблиц» формулами. LAMBDA тут может использоваться, чтобы применять какое-то вычисление к агрегируемым данным. Подробнее об этих функциях и про применение LAMBDA в них можно прочитать в этой моей статье:
Функции ГРУПППО / GROUPBY и СВОДПО / PIVOTBY
А еще можно внутри формулы задать свою собственную функцию, дать ей название с помощью функции LET и далее использовать в вычислении, вызывая по имени. Ух!
Пример, если хочется сразу, можно посмотреть тут:
Одной формулой собираем ТОП-N сделок из всех умных таблиц в списке
А про функцию LET в целом прочитать тут.
Содержание статьи:
К тому же LAMBDA — это не только для того, чтобы создавать свои функции и потом использовать, не вводя их с нуля. LAMBDA позволяет написать функцию, которая будет применяться к каждому элементу массива (для этого понадобится вспомогательная функция MAP), к каждому элементу массива и еще к накопленному итогу на каждом шаге (SCAN и REDUCE), к каждой строке или столбцу (BYROW и BYCOL), к каждому элементу формируемого массива (с возможностью обращения к индексу его строки и столбца - MAKEARRAY)
А еще — только в Excel (не в Google Таблицах) — можно использовать LAMBDA внутри других новых функций ГРУПППО / GROUPBY и СВОДПО / PIVOTBY для формирования «сводных таблиц» формулами. LAMBDA тут может использоваться, чтобы применять какое-то вычисление к агрегируемым данным. Подробнее об этих функциях и про применение LAMBDA в них можно прочитать в этой моей статье:
Функции ГРУПППО / GROUPBY и СВОДПО / PIVOTBY
А еще можно внутри формулы задать свою собственную функцию, дать ей название с помощью функции LET и далее использовать в вычислении, вызывая по имени. Ух!
Пример, если хочется сразу, можно посмотреть тут:
Одной формулой собираем ТОП-N сделок из всех умных таблиц в списке
А про функцию LET в целом прочитать тут.
Содержание статьи:
- Где LAMBDA доступна
- Видео: LAMBDA в Google Таблицах
- LAMBDA: первый подход. Создаем свою функцию
- LAMBDA и необязательный аргумент пользовательской функции с ISOMITTED / ПРОПУЩЕНО
- LAMBDA и MAP
- MAP внутри нашей пользовательской функции
- LAMBDA внутри функции ГРУПППО / GROUPBY. Краткая форма записи eta lambda
- Строим "сводную таблицу" на формулах в Google Таблицах
- Обработка столбцов и строк — функции BYROW и BYCOL
- Функции SCAN и REDUCE: работаем с промежуточными итогами и каждым значением
- Переменная как ссылка на ячейку
- Функции для формирования массивов — EXPAND и MAKEARRAY
- Рекурсия в LAMBDA
- Заключение: не формулами едиными
- Ссылки на дополнительные примеры
- Ссылки на файлы с примерами
Где LAMBDA доступна
В Excel LAMBDA есть только в 2024, 365 и Excel Online.
Пользователям Google Таблиц LAMBDA и почти все вспомогательные функции (кроме ISOMITTED / ПРОПУЩЕНО) доступны. Доступна вся эта радость и в Google Workspace, и в бесплатных аккаунтах. И особенно радует отсутствие проблем совместимости. Если в случае с Excel формулы с новыми функциями будут работать только в новых версиях, а при открытии книг в старых версиях будут возвращать ошибки, то в Google Spreadsheets формулы будут работать у всех.
Пользователям Google Таблиц LAMBDA и почти все вспомогательные функции (кроме ISOMITTED / ПРОПУЩЕНО) доступны. Доступна вся эта радость и в Google Workspace, и в бесплатных аккаунтах. И особенно радует отсутствие проблем совместимости. Если в случае с Excel формулы с новыми функциями будут работать только в новых версиях, а при открытии книг в старых версиях будут возвращать ошибки, то в Google Spreadsheets формулы будут работать у всех.
Видео: LAMBDA в Google Таблицах
Если вы предпочитаете видео-формат и / или работаете в Google Таблицах, посмотрите мой урок по LAMBDA. Тут основы, и статью лучше все равно прочитать :) А видео можно посмотреть как сейчас, так и после прочтения. Для экселье тоже актуально, так как принципы одни и те же. В видео есть сравнение классических формул массив и LAMBDA с MAP и пример, когда последние будут актуальны.
LAMBDA: первый подход
Синтаксис у функции такой:
=LAMBDA ([переменная]; …; [переменная]; формула)
Переменных может и не быть (хотя тогда LAMBDA не имеет особого смысла, можно просто присвоить имени Excel формулу без аргументов и вызывать ее по этому имени), может быть одна или несколько. В конце последним аргументом всегда будет формула с этими переменными.
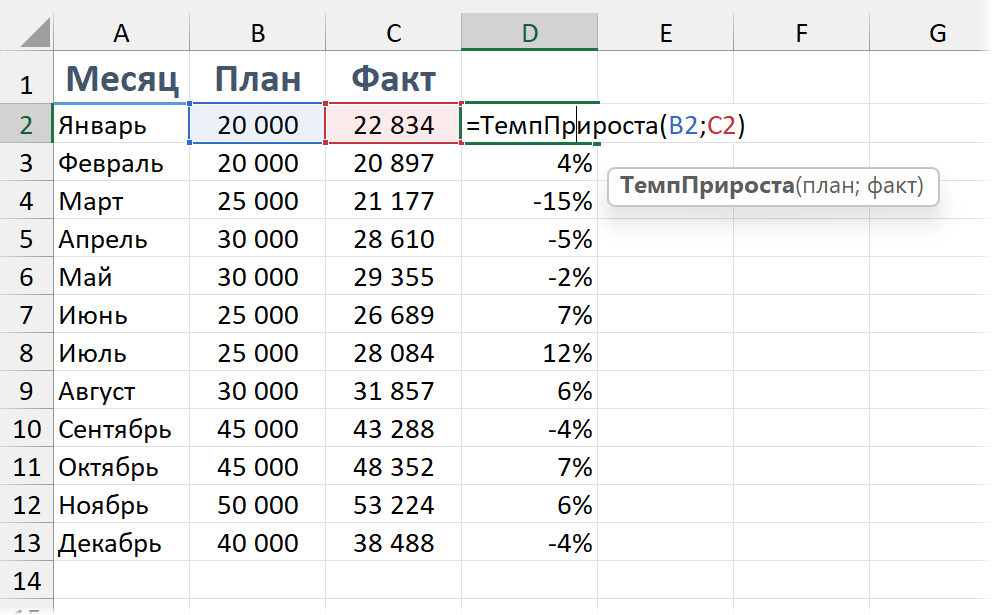
Рассмотрим на простом примере с отклонением факт/план. Допустим, план в столбце B, факт в столбце C. Обычная формула будет выглядеть так:
=C2 / B2 — 1
А в случае с LAMBDA мы указываем переменные и формулу с ними в общем случае:
=LAMBDA (план; факт; факт / план — 1)
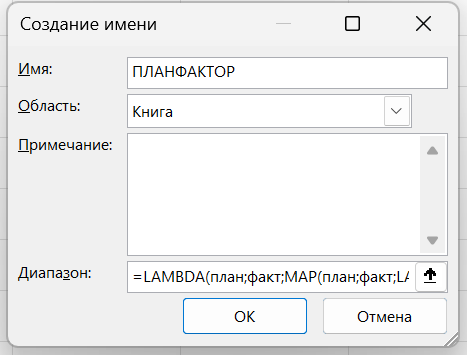
После чего можно сохранить ее в диспетчере имен (Ctrl + F3) под любым именем, какое вы хотите присвоить этой функции — например, «ТемпПрироста». И дальше использовать эту функцию в пределах книги (а если хочется перенести ее в другую — можно скопировать ячейку с формулой и вставить ее в другую книгу — это приведет к переносу имени, а значит, и функции). Если хотите использовать какие-то функции во всех книгах Excel, можно создать пустую книгу, добавить в нее имена с пользовательскими функциями и затем эту книгу сохранить как шаблон новой книги — инструкция тут.
=LAMBDA ([переменная]; …; [переменная]; формула)
Переменных может и не быть (хотя тогда LAMBDA не имеет особого смысла, можно просто присвоить имени Excel формулу без аргументов и вызывать ее по этому имени), может быть одна или несколько. В конце последним аргументом всегда будет формула с этими переменными.
Рассмотрим на простом примере с отклонением факт/план. Допустим, план в столбце B, факт в столбце C. Обычная формула будет выглядеть так:
=C2 / B2 — 1
А в случае с LAMBDA мы указываем переменные и формулу с ними в общем случае:
=LAMBDA (план; факт; факт / план — 1)
После чего можно сохранить ее в диспетчере имен (Ctrl + F3) под любым именем, какое вы хотите присвоить этой функции — например, «ТемпПрироста». И дальше использовать эту функцию в пределах книги (а если хочется перенести ее в другую — можно скопировать ячейку с формулой и вставить ее в другую книгу — это приведет к переносу имени, а значит, и функции). Если хотите использовать какие-то функции во всех книгах Excel, можно создать пустую книгу, добавить в нее имена с пользовательскими функциями и затем эту книгу сохранить как шаблон новой книги — инструкция тут.
Можно также протестировать LAMBDA сразу, без присвоения имени. Для этого достаточно ввести конкретные значения ее аргументов в скобках после функции, например:
=LAMBDA (план; факт; факт / план — 1)(20000; 22500)
=LAMBDA (план; факт; факт / план — 1)(20000; 22500)

LAMBDA и необязательный аргумент пользовательской функции с ISOMITTED / ПРОПУЩЕНО
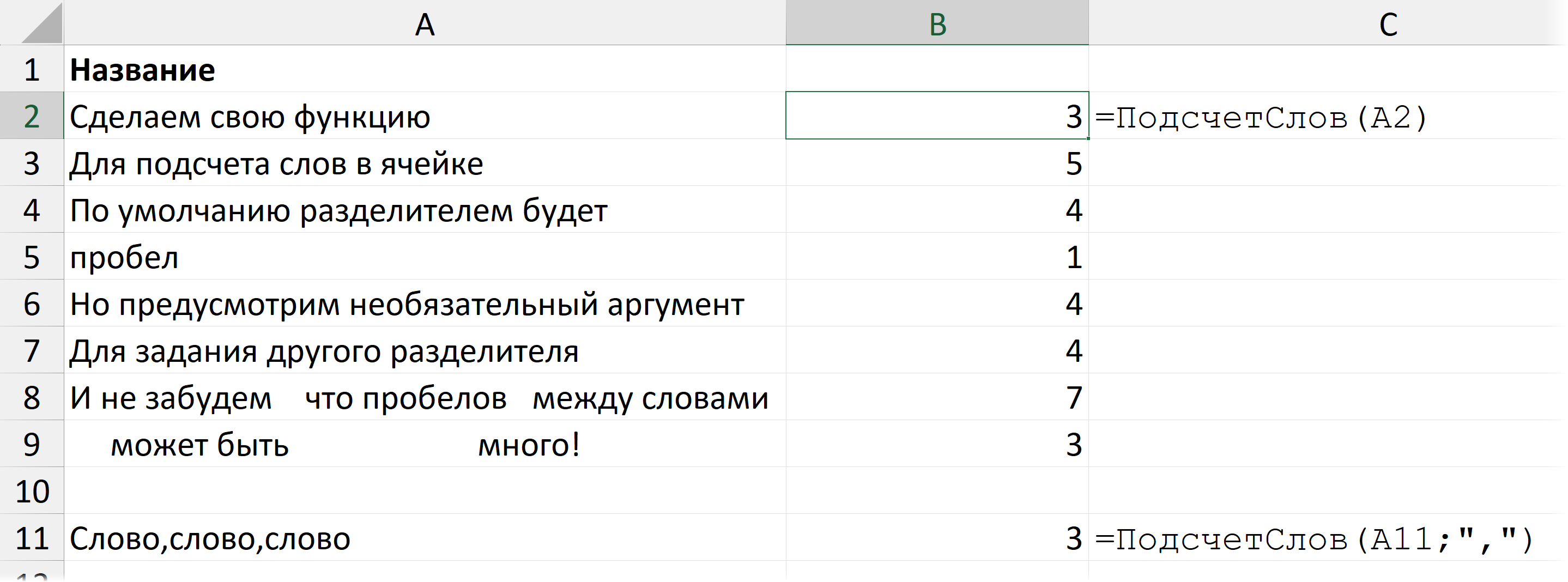
В таких пользовательских функциях можно даже создавать необязательные аргументы — для этого нужна функция ISOMITTED / ПРОПУЩЕНО — она возвращает ИСТИНА / TRUE, когда аргумент пропущен.
Чтобы задать необязательный аргумент, в LAMBDA возьмите его в квадратные скобки. Тогда пользователь сможет его пропускать. И в таком случае стоит предусмотреть (с помощью ПРОПУЩЕНО) ситуацию, когда аргумент будет пропущен.
=LAMBDA (аргумент1;…;[аргументN]; ЕСЛИ (ПРОПУЩЕНО (аргументN); действие, если аргумент пропущен; действие, если аргумент не пропущен))
В книге Excel с примерами к этой статье вы найдете функцию ПодсчетСлов, у которой есть необязательный аргумент — разделитель. По умолчанию это пробел, если аргумент пропущен, но можно задать любой разделитель.
Чтобы задать необязательный аргумент, в LAMBDA возьмите его в квадратные скобки. Тогда пользователь сможет его пропускать. И в таком случае стоит предусмотреть (с помощью ПРОПУЩЕНО) ситуацию, когда аргумент будет пропущен.
=LAMBDA (аргумент1;…;[аргументN]; ЕСЛИ (ПРОПУЩЕНО (аргументN); действие, если аргумент пропущен; действие, если аргумент не пропущен))
В книге Excel с примерами к этой статье вы найдете функцию ПодсчетСлов, у которой есть необязательный аргумент — разделитель. По умолчанию это пробел, если аргумент пропущен, но можно задать любой разделитель.
Сама функция выглядит так:
=LAMBDA(текст;[разделитель];
ДЛСТР(СЖПРОБЕЛЫ(текст)) - ДЛСТР(ПОДСТАВИТЬ(СЖПРОБЕЛЫ(текст); ЕСЛИ(ПРОПУЩЕНО(разделитель);" ";разделитель);""))+1)
=LAMBDA(текст;[разделитель];
ДЛСТР(СЖПРОБЕЛЫ(текст)) - ДЛСТР(ПОДСТАВИТЬ(СЖПРОБЕЛЫ(текст); ЕСЛИ(ПРОПУЩЕНО(разделитель);" ";разделитель);""))+1)
LAMBDA и MAP
Если мы хотим что-то сделать с каждым значением из диапазона или массива (или из нескольких диапазонов) — можем использовать функцию MAP.
=MAP (массив; LAMBDA (переменная для обозначения каждого элемента массива; вычисление))
Если диапазонов или массивов несколько, будет так:
=MAP (массив1; массив2;… LAMBDA (переменная для обозначения каждого элемента массива1; переменная для каждого элемента массива2;…; вычисление))
=MAP (массив; LAMBDA (переменная для обозначения каждого элемента массива; вычисление))
Если диапазонов или массивов несколько, будет так:
=MAP (массив1; массив2;… LAMBDA (переменная для обозначения каждого элемента массива1; переменная для каждого элемента массива2;…; вычисление))
Например, мы можем взять массив с суммами сделок (из таблицы) — и умножить каждое значение на 10%. Первый аргумент функции MAP — массив с данными (здесь ссылка на столбец «Сумма» таблицы Сделки. Второй — функция LAMBDA, у которой первый аргумент — это переменная (произвольное имя, у нас — стоимость) для каждого элемента массива, а второй — вычисление с этой переменной (что мы делаем с каждым элементом из массива).
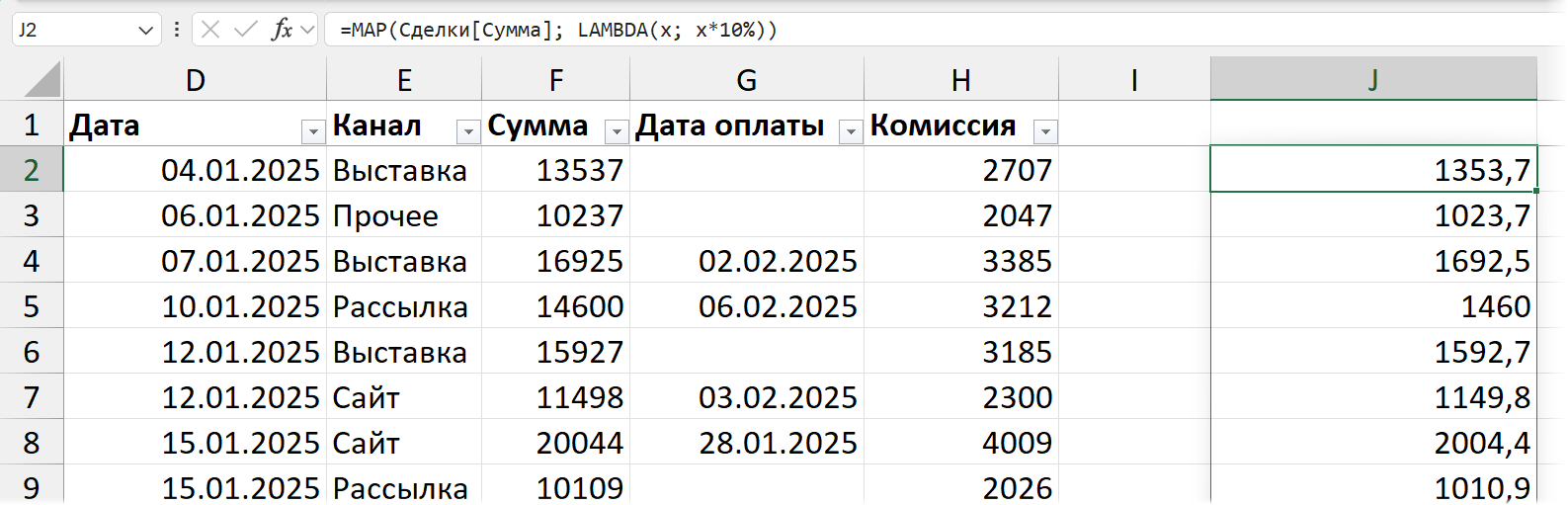
Конечно, такую задачу можно решить и обычной формулой, и формулой массива — это лишь пример, показывающий, что позволяет делать MAP.
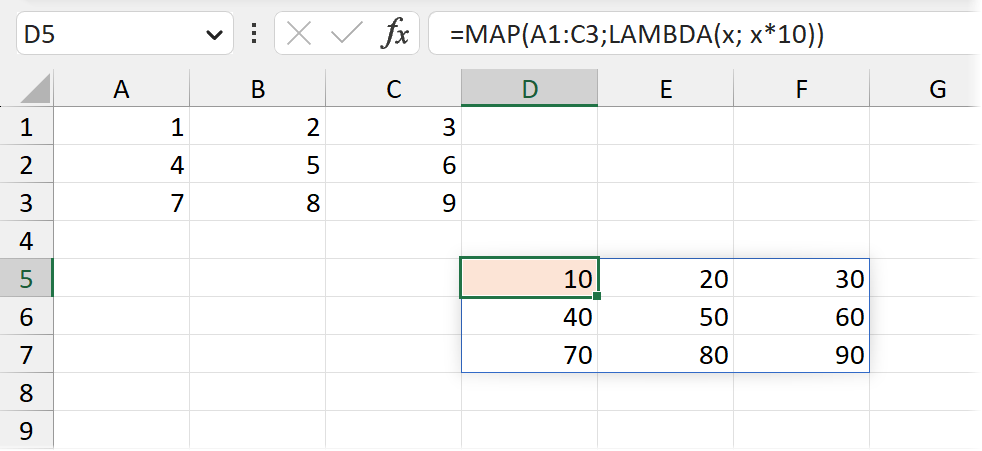
Если массив двумерный — то и результат будет такого же размера. MAP применяет вычисление к каждому элементу массива:
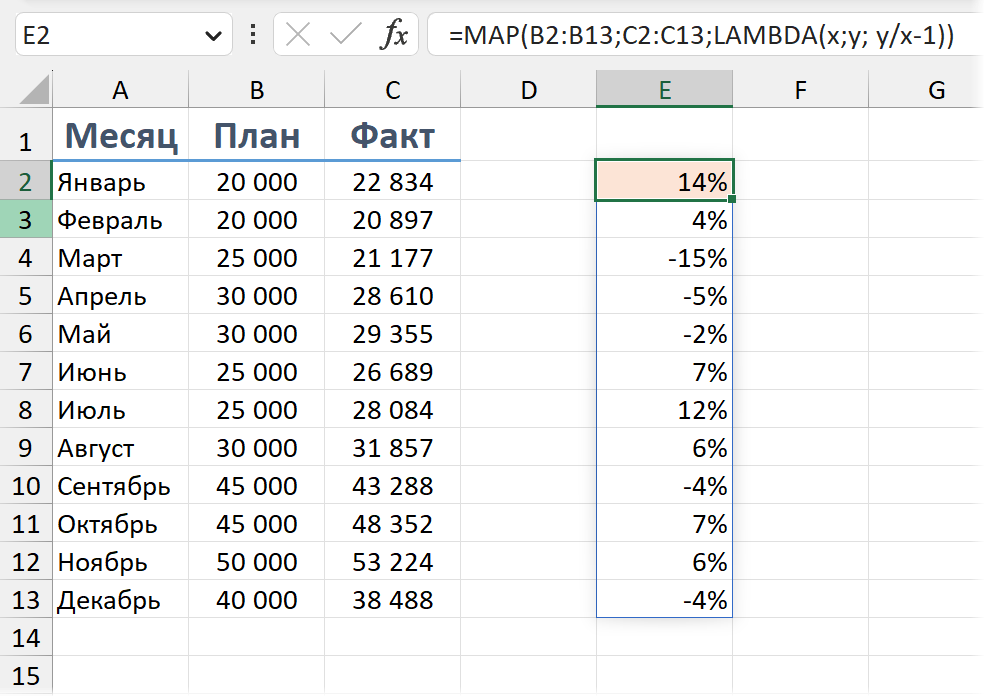
А вот пример с использованием нескольких массивов: ссылаемся в MAP на столбцы с планом и фактом. В LAMBDA первая переменная задана как x — в итоговой формуле за этим x будет скрываться каждое значение из первого массива, отправленного в MAP, то есть в нашем случае B2: B13. Переменная y, соответственно, это значение из диапазона C2: C13.
MAP внутри нашей пользовательской функции
А что если мы хотим не разово MAP’ом обработать два массива, как в примере выше, а сделать свою функцию, которая принимает на входе массивы и что-то с ними делает? Почему нет!
Берем нашу предыдущую функцию. Назовем переменные в ней «п» и «ф» (план и факт):
=MAP (B2:B13;C2:C13; LAMBDA (п;ф; ф/п-1))
И заменим конкретные диапазоны переменными, засунув все это добро внутрь еще одной LAMBDA:
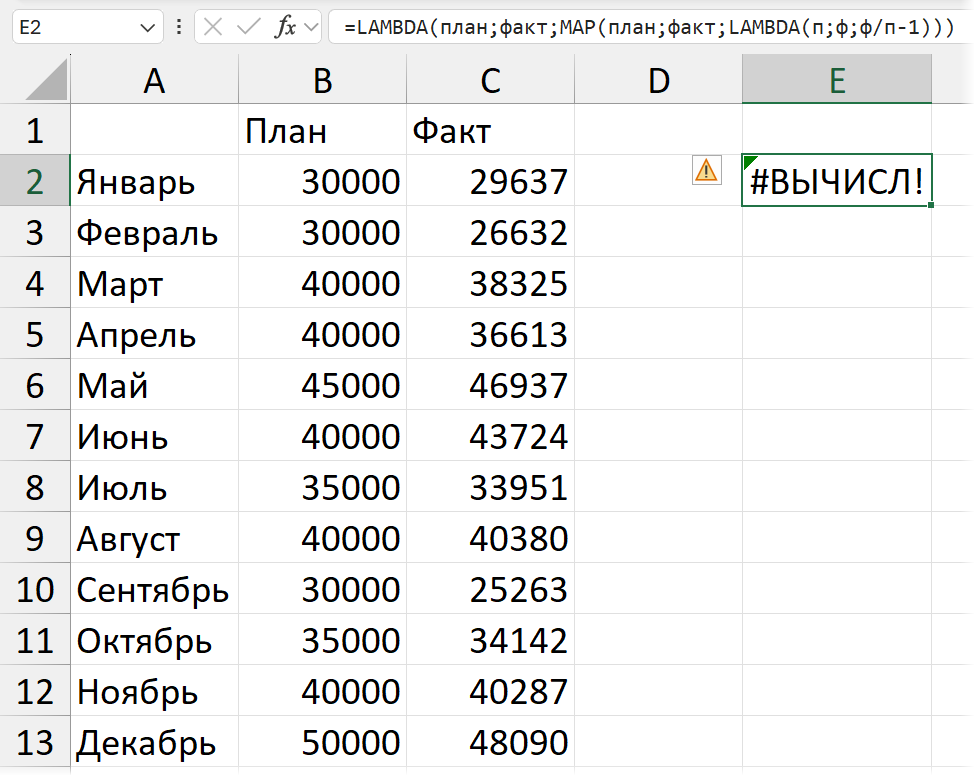
=LAMBDA (план;факт;MAP (план;факт; LAMBDA (п;ф;ф/п-1)))
Такая функция будет возвращать ошибку, так как нет конкретных значений:
Берем нашу предыдущую функцию. Назовем переменные в ней «п» и «ф» (план и факт):
=MAP (B2:B13;C2:C13; LAMBDA (п;ф; ф/п-1))
И заменим конкретные диапазоны переменными, засунув все это добро внутрь еще одной LAMBDA:
=LAMBDA (план;факт;MAP (план;факт; LAMBDA (п;ф;ф/п-1)))
Такая функция будет возвращать ошибку, так как нет конкретных значений:
Проверим ее, добавив в скобках после формулы ссылки на конкретные диапазоны:
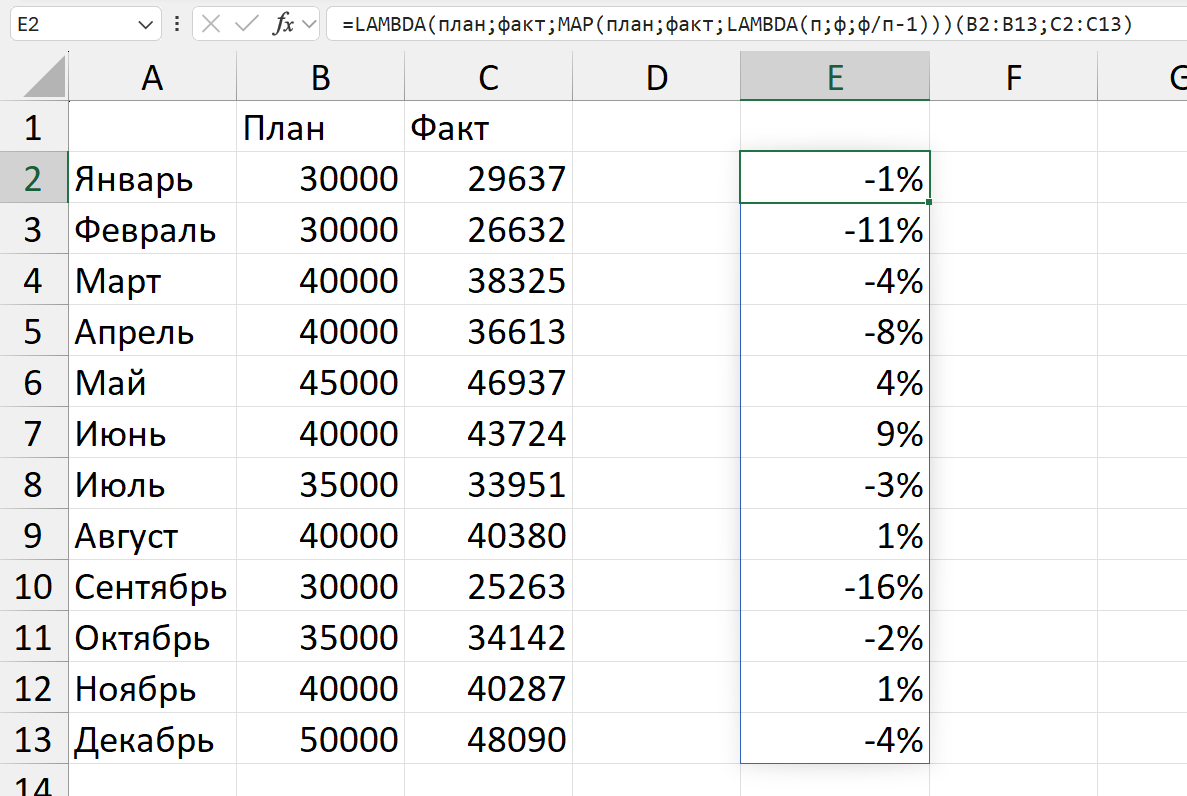
Ну вот. Можно эту функцию теперь отправить в имя и использовать для диапазонов (разных размеров, а не только из 12 ячеек!)
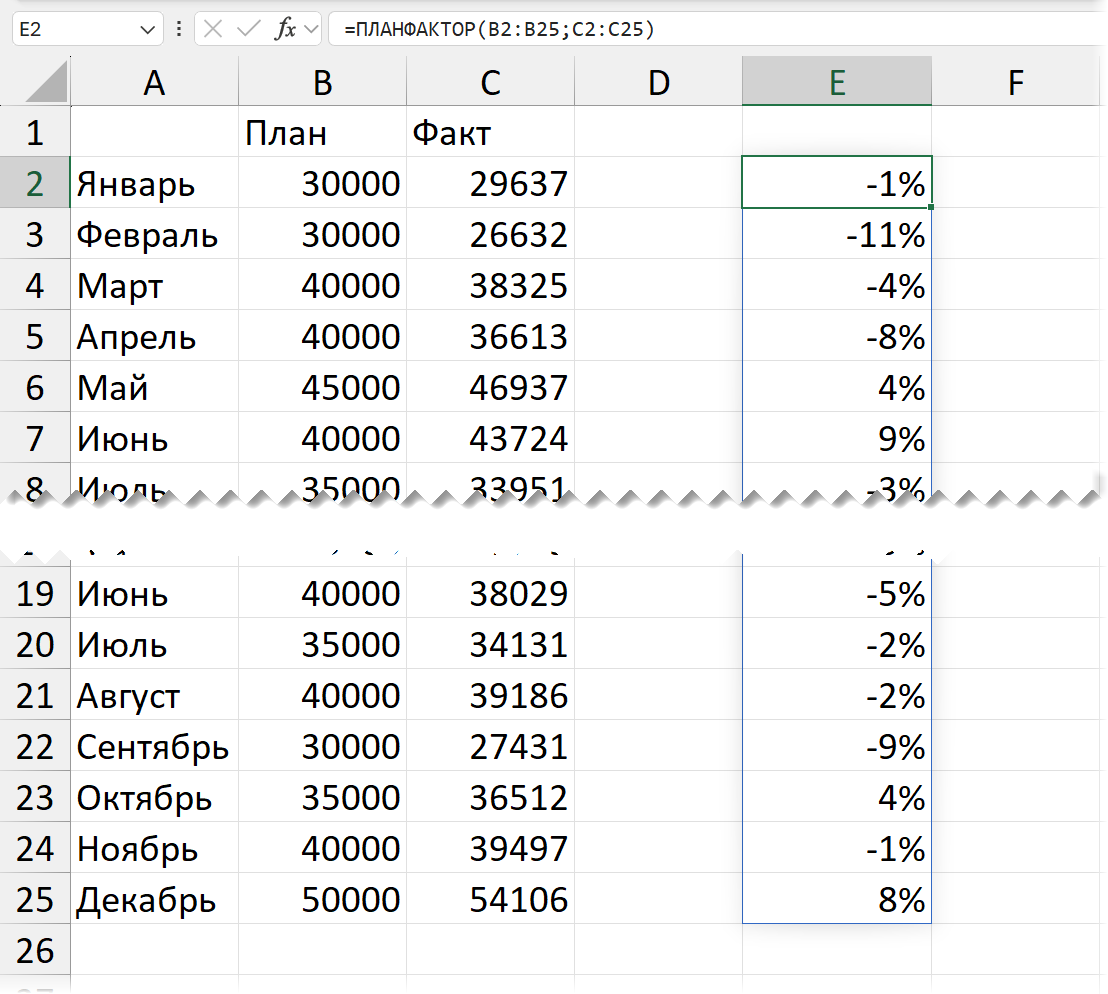
Проверим на диапазоне большего размера:
LAMBDA внутри функции ГРУПППО / GROUPBY. Краткая форма записи eta lambda
Есть такие новые функции ГРУПППО и СВОДПО — позволяют строить сводные на формулах.
И вот в них есть возможность не просто выбирать вычисление, как в обычных сводных (сумма, среднее значение и так далее), но и задавать формулу, которая будет применяться к агрегированным данным. Подробнее про эти функции можно прочитать в моей статье, посвященной им.
А здесь кратко покажу, как LAMBDA используется в ГРУПППО.
В этой функции несколько аргументов — что выводить в «области строк», что в «области значений» и какое вычисление применять.
И вот выглядят варианты вычислений:
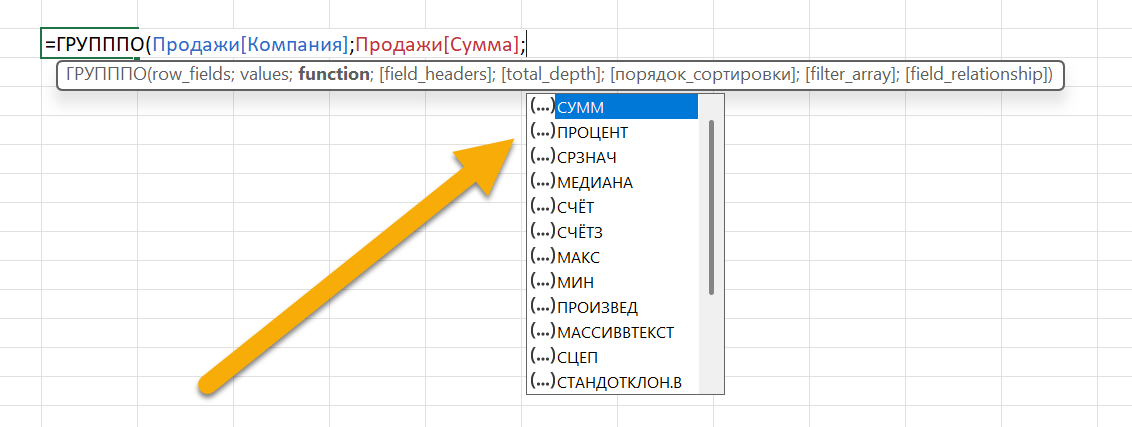
Это на самом деле короткая запись LAMBDA — без аргументов. В такой форме пропускается аргумент, если с ним ничего дополнительно не происходит, иначе говоря, запись
ПРОЦЕНТ
эквивалентна записи:
LAMBDA (x; ПРОЦЕНТ (x))
x — это лишь название переменной, того, что мы даем «на вход». Оно может быть и другим, важно другое: если мы ничего не делаем с тем, что получаем на входе, а только применяем функцию, то мы можем вообще не задавать для этого самого входа название единственной переменной, а просто сказать:
ПРОЦЕНТ или СУММ.
И получается, что мы можем как выбирать один из этих предлагаемых вариантов, так и написать свой! Через LAMBDA. Которая, собственно, в этом списке вариантов есть на последнем месте.
В таком случае нам уже нужно будет задать какую-то переменную. Как ее назвать, решайте сами. Главное понимать, что будет за кулисами этого имени. А будут там данные, агрегированные в контексте, который мы задали через область строк. Все как в обычной сводной.
Можно это визуализировать, чтобы наглядно увидеть. В следующей функции у меня в строках компании, а в области значений — города, где совершались сделки. Что если просто попросить функцию выдать сами эти города, не производя никаких дополнительных манипуляций?
ПРОЦЕНТ
эквивалентна записи:
LAMBDA (x; ПРОЦЕНТ (x))
x — это лишь название переменной, того, что мы даем «на вход». Оно может быть и другим, важно другое: если мы ничего не делаем с тем, что получаем на входе, а только применяем функцию, то мы можем вообще не задавать для этого самого входа название единственной переменной, а просто сказать:
ПРОЦЕНТ или СУММ.
И получается, что мы можем как выбирать один из этих предлагаемых вариантов, так и написать свой! Через LAMBDA. Которая, собственно, в этом списке вариантов есть на последнем месте.
В таком случае нам уже нужно будет задать какую-то переменную. Как ее назвать, решайте сами. Главное понимать, что будет за кулисами этого имени. А будут там данные, агрегированные в контексте, который мы задали через область строк. Все как в обычной сводной.
Можно это визуализировать, чтобы наглядно увидеть. В следующей функции у меня в строках компании, а в области значений — города, где совершались сделки. Что если просто попросить функцию выдать сами эти города, не производя никаких дополнительных манипуляций?
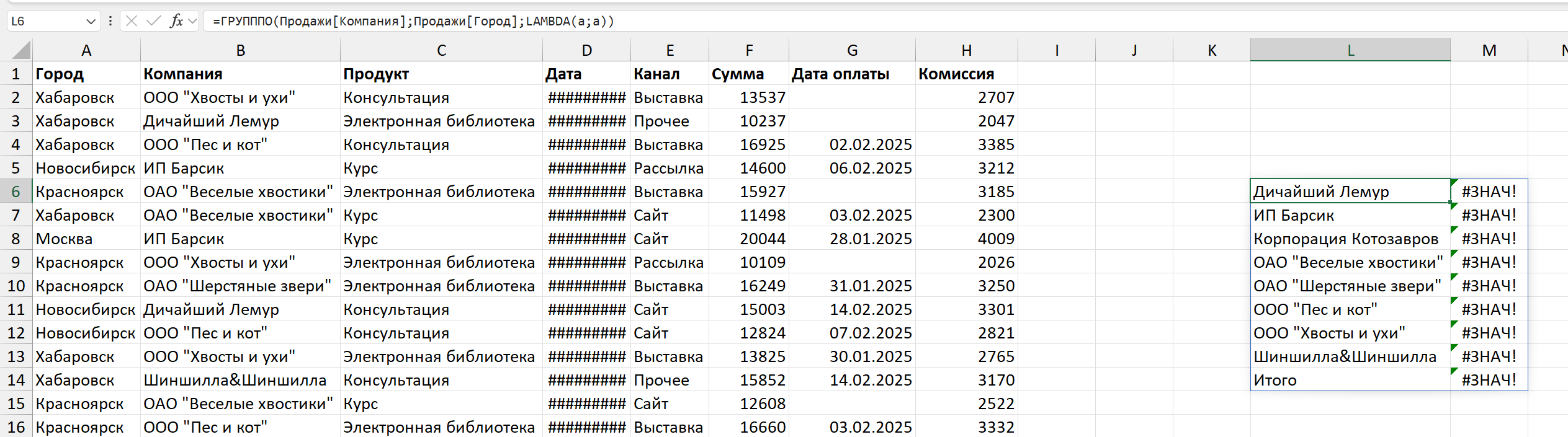
Не выйдет! Будет ошибка. Дело в том, что тут, как в классической сводной — результат должен быть в одной ячейке, агрегированным. Так что надо применить какую-то функцию, которая выдаст одно значение. Не обязательно числовое, в отличие от классической сводной.
Ну давайте попросим просто все склеить функцией СЦЕП / CONCAT:
Ну давайте попросим просто все склеить функцией СЦЕП / CONCAT:
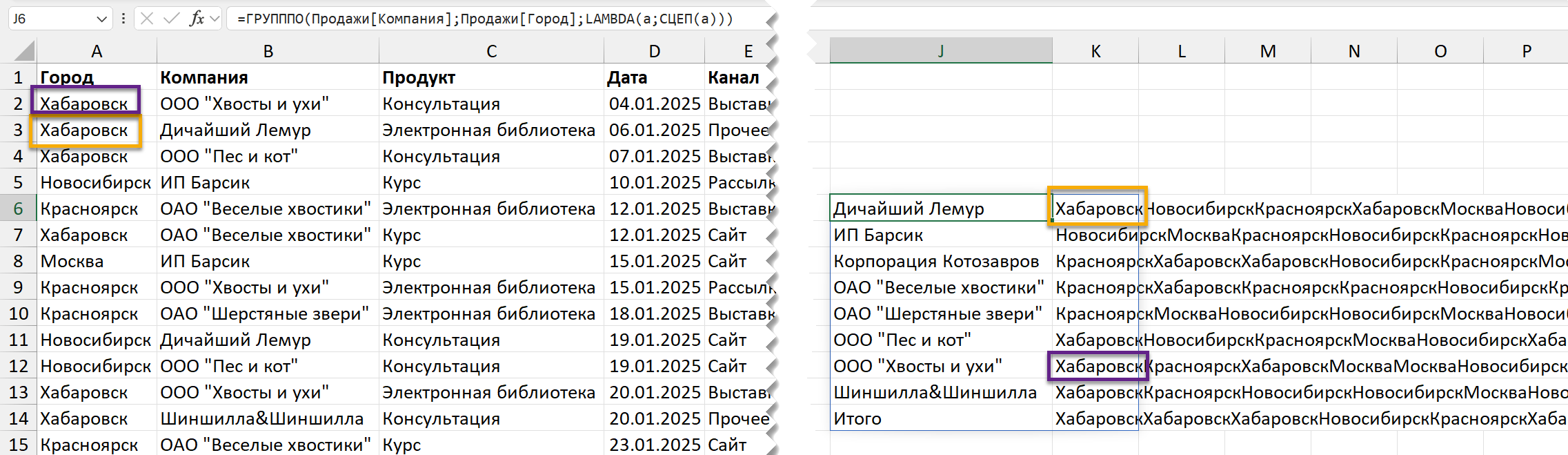
И вот увидим буквально, что будет в нашей переменной a или x — все значения по каждой компании из столбца «Город». Мы получаем к ним доступ и можем писать формулу, которая будет вычисляться в каждой ячейке и что-то делать с массивом значений — в данном случае со списком городов каждого клиента.
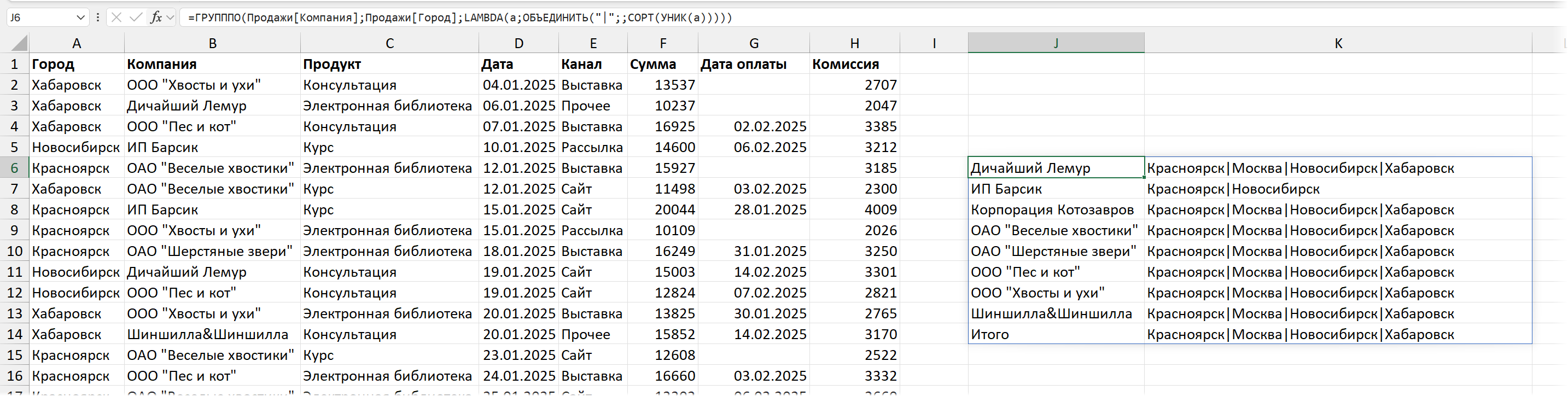
Если мы хотим их вывести в алфавитном порядке и без повторов, добавим функции УНИК / UNIQUE (чтобы каждый город, в котором была сделка, встречался один раз) и СОРТ / SORT (для сортировки)
=ГРУПППО (Продажи[Компания];Продажи[Город];
LAMBDA (a;ОБЪЕДИНИТЬ ("|";;СОРТ (УНИК (a)))))
Видно, что по всем компаниям сделки были во всех четырех городах, кроме одной — И П Барсик:
Если мы хотим их вывести в алфавитном порядке и без повторов, добавим функции УНИК / UNIQUE (чтобы каждый город, в котором была сделка, встречался один раз) и СОРТ / SORT (для сортировки)
=ГРУПППО (Продажи[Компания];Продажи[Город];
LAMBDA (a;ОБЪЕДИНИТЬ ("|";;СОРТ (УНИК (a)))))
Видно, что по всем компаниям сделки были во всех четырех городах, кроме одной — И П Барсик:
Строим "сводную таблицу" на формулах в Google Таблицах
Хотя в Google Таблицах нет функций ГРУПППО / GROUPBY и СВОДПО / PIVOTBY, когда у вас есть LAMBDA, вы почти всемогущи :)
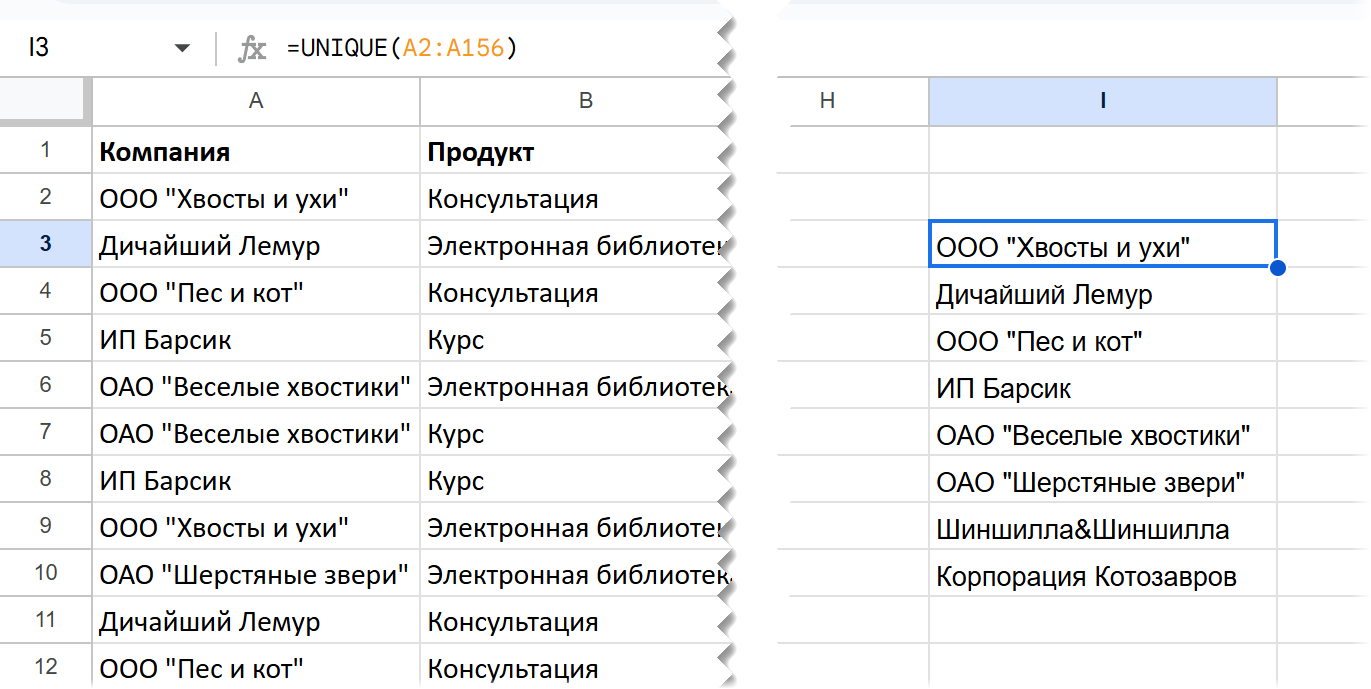
Например, мы хотим получить такой же текстовый результат, только список продуктов, которые покупал каждый из наших клиентов.
В классической сводной мы бы перетащили поле «Клиент» в область строк. И получили бы уникальные значения в строках — по одному на каждого клиента. Как получить такой результат на формулах, что будет выступать аргументом функции MAP?
Очевидно, не просто диапазон с именами клиентов в нашей таблице. Ведь там они повторяются.
Нам нужны имена клиентов без повторов — так что в MAP мы отправим только уникальные значения, которые получим с помощью UNIQUE (в Excel на русском — УНИК, а в Google Таблицах эта функция всегда на английском).
Например, мы хотим получить такой же текстовый результат, только список продуктов, которые покупал каждый из наших клиентов.
В классической сводной мы бы перетащили поле «Клиент» в область строк. И получили бы уникальные значения в строках — по одному на каждого клиента. Как получить такой результат на формулах, что будет выступать аргументом функции MAP?
Очевидно, не просто диапазон с именами клиентов в нашей таблице. Ведь там они повторяются.
Нам нужны имена клиентов без повторов — так что в MAP мы отправим только уникальные значения, которые получим с помощью UNIQUE (в Excel на русском — УНИК, а в Google Таблицах эта функция всегда на английском).
Что теперь нужно по каждой из компаний получить? Ее продукты. Будем выбирать продукты каждого клиента в списке уникальных с помощью функции FILTER (по сути, ей мы заменим встроенный фильтр экселевской функции ГРУПППО) и склеить в одну текстовую строку с помощью JOIN:
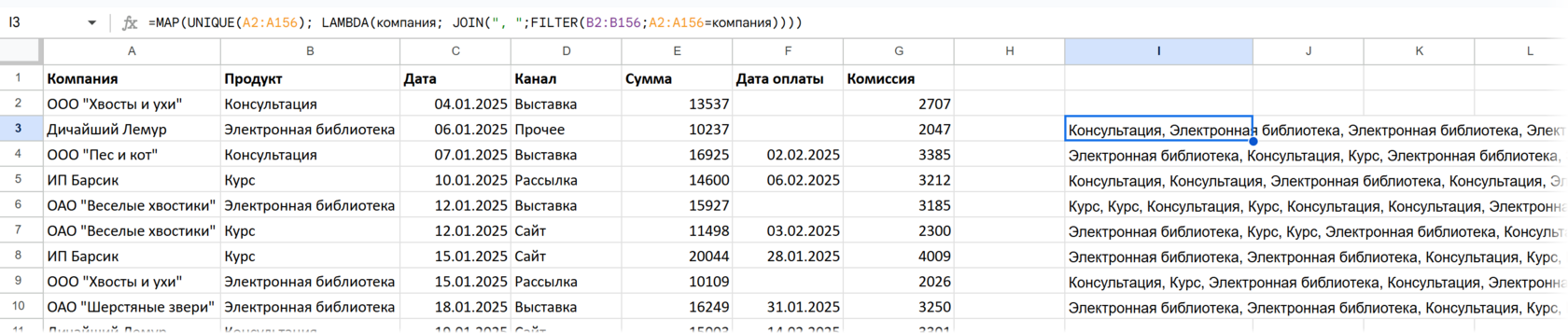
Что видим? Во-первых, нет названия самой компании. Во-вторых, есть повторы — на каждую консультацию, купленную компанией, будет это слово в результате. А нам надо один раз — покупали такой продукт в принципе или нет. Так что, как и в примере с ГРУПППО выше, добавляем UNIQUE и заодно SORT для одинакового порядка:
=MAP(UNIQUE(Сделки[Компания]); LAMBDA(компания; JOIN(",";SORT(UNIQUE(FILTER(Сделки[Продукт];Сделки[Компания]=компания))))))
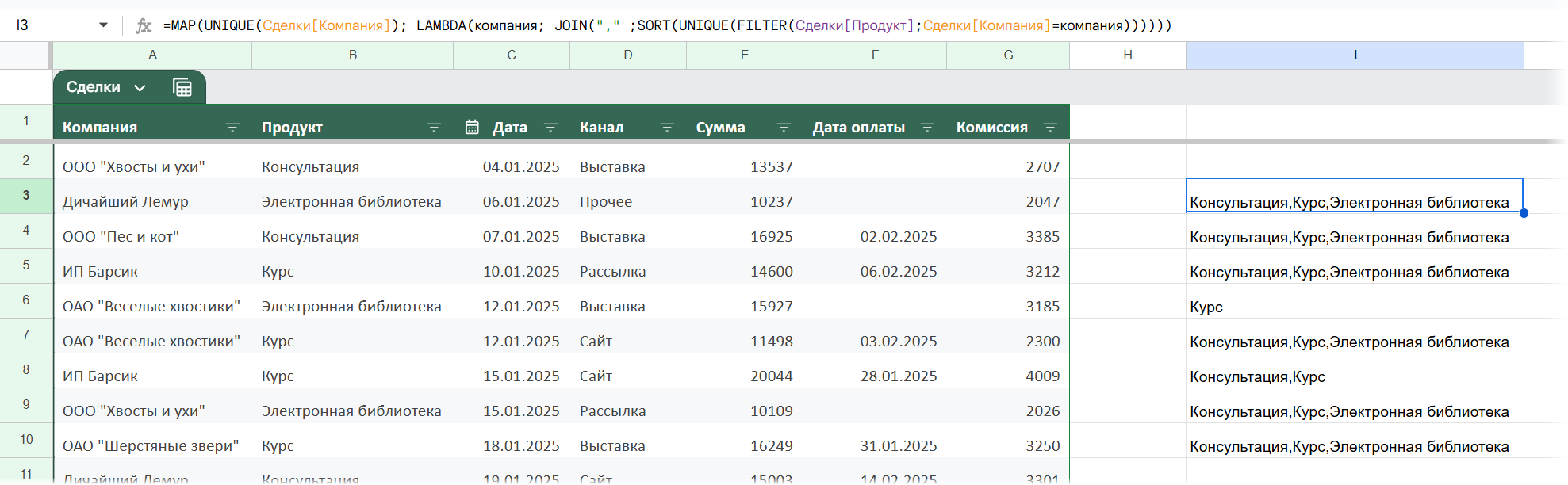
Уже веселее! Осталось добавить названия компаний, собственно, а то как понять, что к чему относится?
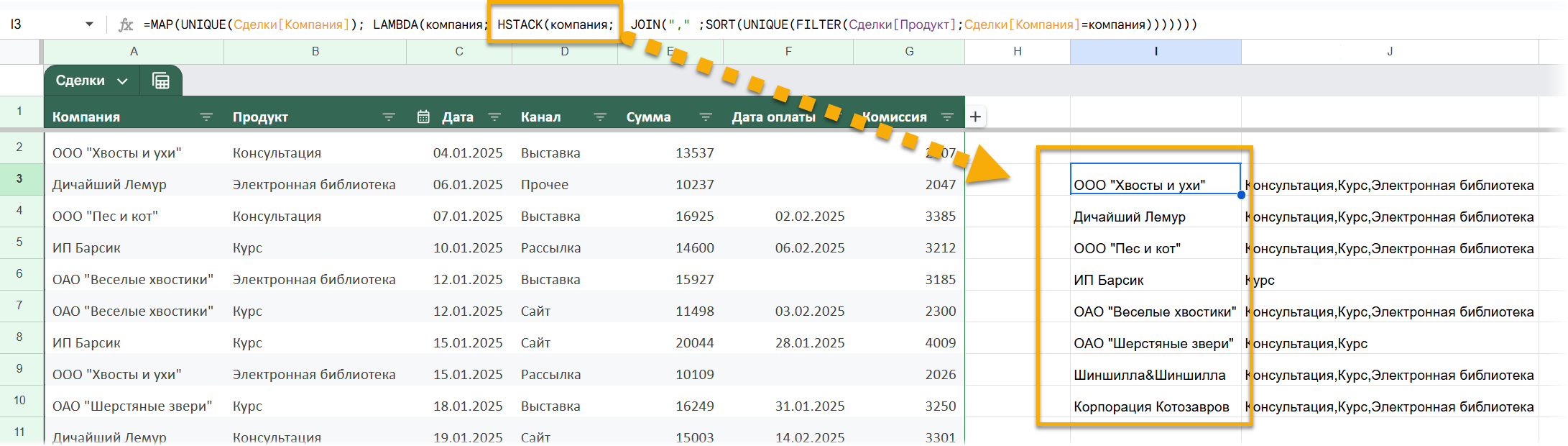
Чтобы это было в отдельном столбце, используем HSTACK, функцию, объединяющую массивы горизонтально (в Excel на русском у нее милое название ГСТОЛБИК):
Чтобы это было в отдельном столбце, используем HSTACK, функцию, объединяющую массивы горизонтально (в Excel на русском у нее милое название ГСТОЛБИК):
Обработка столбцов и строк — функции BYROW и BYCOL
Функция BYROW позволяет последовательно обращаться к каждой строке в массиве.
Ее синтаксис:
=BYROW (диапазон;
LAMBDA (переменная для обращения к каждой строке); вычисление с этой переменной))
LAMBDA (переменная для обращения к каждой строке); вычисление с этой переменной))
То есть мы можем производить вычисления не с отдельной ячейкой и не со всем массивом, а с каждой строкой последовательно (на выходе мы получим массив значений в один столбец и с таким же числом строк, сколько в исходном диапазоне — это будет результат вычисления с каждой строкой). Де-факто получается цикл — мы обрабатываем каждую строку последовательно.
Аналогично работает функция BYCOL — там, соответственно, будет обрабатываться каждый столбец массива.
Давайте посмотрим на пример. У нас диапазон C2: N13, в котором есть продажи за 12 месяцев. Посчитаем средние продажи в каждой строке одной формулой:
=BYROW (C2:N13; LAMBDA (строка;СРЗНАЧ (строка)))

Конечно, мы могли бы просто протянуть формулу =СРЗНАЧ (C2:N2) на несколько строк. Но этот пример показывает нам, как работает BYROW. Без нее одной формулой не получится — если ввести функцию СРЗНАЧ и сослаться на весь диапазон C2: N13 — мы получим среднее по всем месяцам (столбцам) и продуктам (строкам), по всему двумерному диапазону.
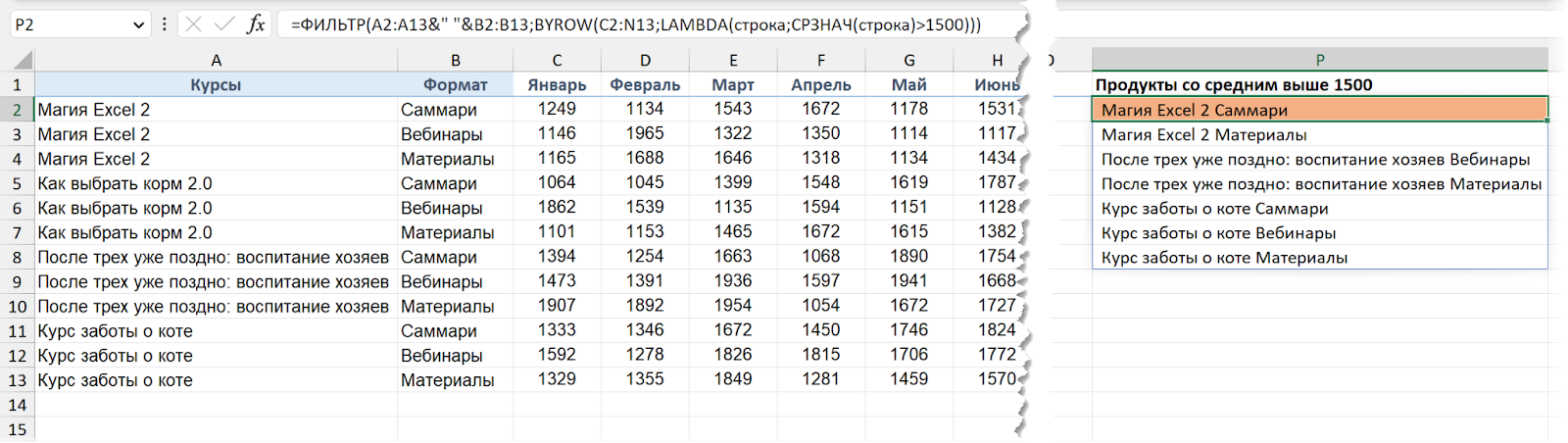
Теперь давайте решим другую задачу: нам нужно выводить те продукты (сочетание: какой курс и какой формат — вебинары или саммари), у которых средняя выручка за год — выше 1500. Например, Магия Excel 2 + саммари — нужно выводить (среднее — 1522), а Как выбрать корм 2.0 + вебинары — нет (среднее — 1459).
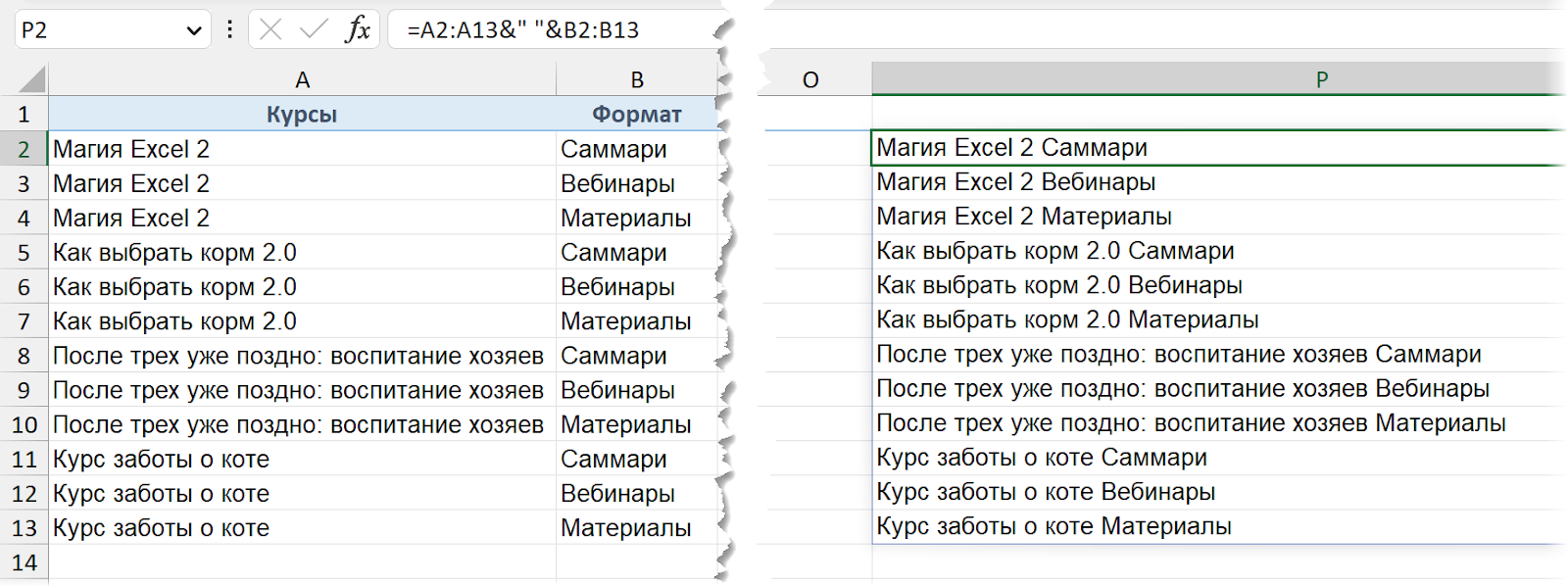
Чтобы получать комбинацию «Курс — Формат», объединим два столбца амперсандом и добавим между ними разделитель — например, пробел:
A2:A13&" "&B2:B13
А чтобы вывести из этого виртуального (виртуального, потому что мы не будем, конечно, выводить его в ячейки отдельно в итоговой формуле, как выше — это сделано лишь для того, чтобы мы посмотрели, как выглядит промежуточный результат) списка только те значения, которые соответствуют нашему условию (Среднее выше 1500), применим функцию ФИЛЬТР / FILTER. В общем виде так:
=ФИЛЬТР(A2:A13&" "&B2:B13; Среднее > 1500)
Ну а на деле, чтобы получить среднее по каждой строке, используем BYROW, как делали это выше:
=ФИЛЬТР(A2:A13&" " &B2:B13; BYROW(C2:N13;LAMBDA(строка;СРЗНАЧ(строка)>1500)))
Функции SCAN и REDUCE: работаем с промежуточными итогами и каждым значением
SCAN и REDUCE позволяют работать как с каждым значением, так и с промежуточным итогом. И выводить все шаги (SCAN) или только последний (REDUCE).
Синтаксис у функций следующий:
=SCAN (начальное значение; массив; LAMBDA (…))
Последний аргумент — это функция LAMBDA, в которой первый аргумент — это нарастающий итог (накопленный результат) второй — это отдельное значение (на первом шаге — начальное значение, заданное в первом аргументе SCAN, а далее — каждое очередное значение из массива), третий — вычисление:
=SCAN (начальное значение; массив;
LAMBDA (нарастающий итог; значение; вычисление))
Нарастающий итог и значение в функции LAMBDA можно назвать как угодно — acc и value, итог и значение, state и current, s и c - как угодно. Главное, что под первым названием в LAMBDA внутри SCAN или REDUCE будет промежуточный итог, а под вторым очередное значение из массива.
Вот отдельная подробная статья про эти функции — по ссылке.
Синтаксис у функций следующий:
=SCAN (начальное значение; массив; LAMBDA (…))
Последний аргумент — это функция LAMBDA, в которой первый аргумент — это нарастающий итог (накопленный результат) второй — это отдельное значение (на первом шаге — начальное значение, заданное в первом аргументе SCAN, а далее — каждое очередное значение из массива), третий — вычисление:
=SCAN (начальное значение; массив;
LAMBDA (нарастающий итог; значение; вычисление))
Нарастающий итог и значение в функции LAMBDA можно назвать как угодно — acc и value, итог и значение, state и current, s и c - как угодно. Главное, что под первым названием в LAMBDA внутри SCAN или REDUCE будет промежуточный итог, а под вторым очередное значение из массива.
Вот отдельная подробная статья про эти функции — по ссылке.
Переменная как ссылка на ячейку
Здесь можно увидеть, что при обработке диапазона с помощью MAP и LAMBDA переменная, которую вы придумаете, соответствует ссылке (ячейке) — и этим можно пользоваться.
Допустим, хотите вы сформировать нумерацию в рамках группы — то есть считать, сколько раз встречается то значение, которое есть в этой строке, в диапазоне от начала всей таблицы до этой самой текущей строки.
Вполне можно все сделать одной формулой: ссылаемся на диапазон в MAP, и в функции СЧЁТЕСЛИ / COUNTIF ссылаемся на диапазон от A1 (или другой ячейки, в которой у вас начинается диапазон для подсчета) и до… переменной, которую вы зададите в LAMBDA:
=MAP (A2:A; LAMBDA (_a; ЕСЛИ (ЕПУСТО (_a);; СЧЁТЕСЛИ (A1:_a; _a))))
Для случаев, когда в столбце A пусто, мы возвращаем пустоту. Отсюда проверка через ЕСЛИ / IF и функцию ЕПУСТО / ISBLANK.
Допустим, хотите вы сформировать нумерацию в рамках группы — то есть считать, сколько раз встречается то значение, которое есть в этой строке, в диапазоне от начала всей таблицы до этой самой текущей строки.
Вполне можно все сделать одной формулой: ссылаемся на диапазон в MAP, и в функции СЧЁТЕСЛИ / COUNTIF ссылаемся на диапазон от A1 (или другой ячейки, в которой у вас начинается диапазон для подсчета) и до… переменной, которую вы зададите в LAMBDA:
=MAP (A2:A; LAMBDA (_a; ЕСЛИ (ЕПУСТО (_a);; СЧЁТЕСЛИ (A1:_a; _a))))
Для случаев, когда в столбце A пусто, мы возвращаем пустоту. Отсюда проверка через ЕСЛИ / IF и функцию ЕПУСТО / ISBLANK.
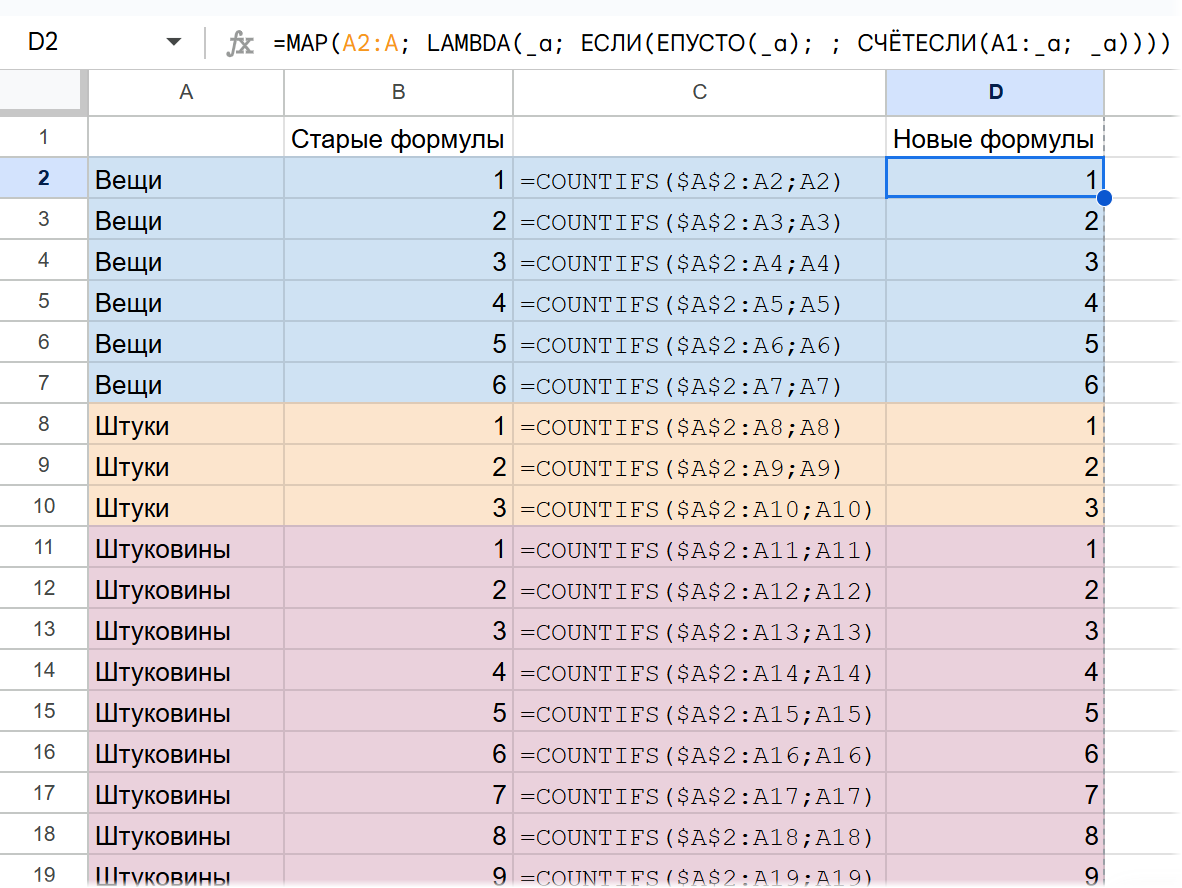
Скриншот с примером в Google Таблицах (он есть в таблице с примерами — ссылка в конце статьи). В строке формул видна одна новая формула. А на старых формулах решение в столбцах B (сами формулы) и C (текст формул). Такие придется протягивать вручную — для каждой строки в таблице.
Еще пример использования переменной в качестве ссылки — в функции SCAN из статьи, ссылку на которую я давал выше (там можно посмотреть подробнее). Допустим, вы хотите нарастающий итог с условием. И условие где-то в соседнем столбце — рядом со значениями. Вы вполне можете ссылаться на этот соседний столбец через функцию СМЕЩ / OFFSET, задавая отступ от значения. В общем виде:
= SCAN (нач значение; диапазон; LAMBDA (acc; val; ЕСЛИ (СМЕЩ (val; 0; отступ по столбцам) = «условие»; …; …)))
Еще пример использования переменной в качестве ссылки — в функции SCAN из статьи, ссылку на которую я давал выше (там можно посмотреть подробнее). Допустим, вы хотите нарастающий итог с условием. И условие где-то в соседнем столбце — рядом со значениями. Вы вполне можете ссылаться на этот соседний столбец через функцию СМЕЩ / OFFSET, задавая отступ от значения. В общем виде:
= SCAN (нач значение; диапазон; LAMBDA (acc; val; ЕСЛИ (СМЕЩ (val; 0; отступ по столбцам) = «условие»; …; …)))
Функции для формирования массивов — EXPAND и MAKEARRAY
MAKEARRAY позволяет сформировать массив значений с заданным числом строк и столбцов и LAMBDA-формулой для каждого значения — с возможностью ссылаться на номер строки и столбца.
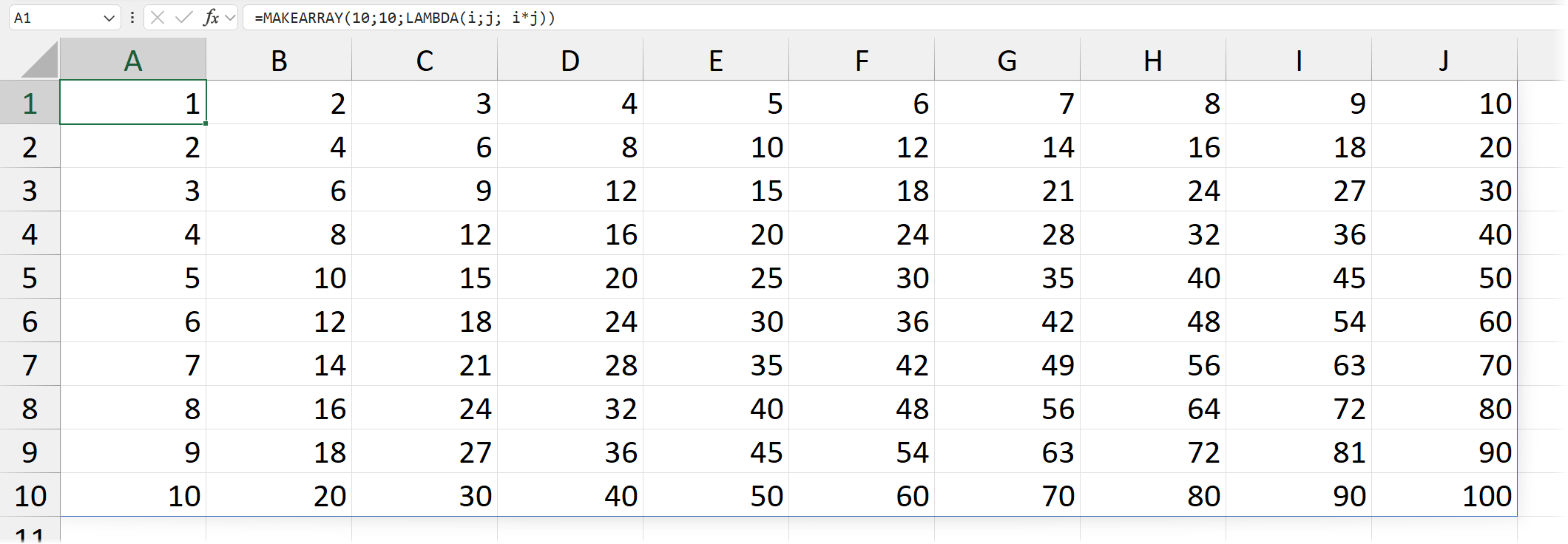
В следующем примере формируем таблицу умножения. Первые два аргумента — 10 и 10 — это число строк и столбцов соответственно.
Далее формируем функцию, которая перемножает номер строки (назвали его i; а можно было r или row или как угодно) и номер столбца (j; а можно было c, например):
В следующем примере формируем таблицу умножения. Первые два аргумента — 10 и 10 — это число строк и столбцов соответственно.
Далее формируем функцию, которая перемножает номер строки (назвали его i; а можно было r или row или как угодно) и номер столбца (j; а можно было c, например):
А если вам в принципе не нужно использовать номер столбца и строки каждого элемента? А просто сформировать массив чего-то. Тогда переменные задаем, но не используем:
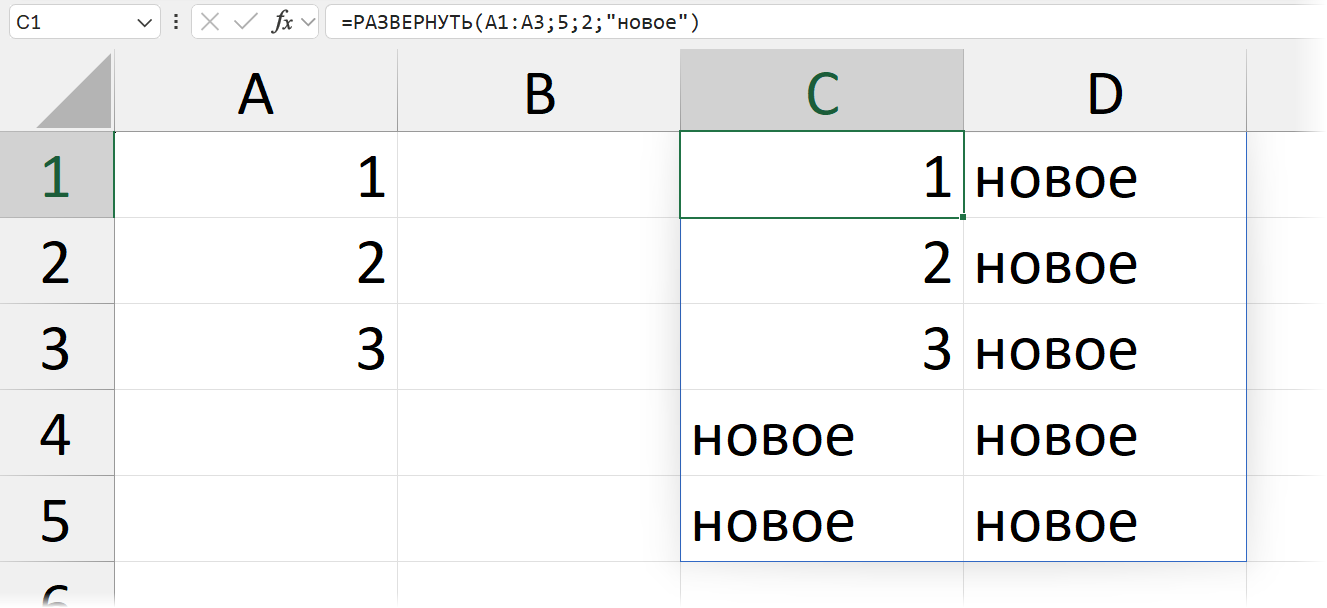
EXPAND / РАЗВЕРНУТЬ к LAMBDA, в общем, отношения прямого не имеет, так как она просто увеличивает размеры массива и заполняет «новые» значения ошибками. Вот есть у нас массив из трех чисел в диапазоне A1: A3. Ссылаемся на него (первый аргумент EXPAND) и увеличиваем число строк (второй аргумент) до 5:

То есть функцию мы тут не задаем, LAMBDA нет. Да еще и новые значения заполняются ошибками. Но ошибки можно заменить — для этого есть четвертый аргумент, после числа столбцов:
И тогда функция очень даже может пригодиться при сборе данных с LAMBDA и вспомогательными функциями из нескольких таблиц и прочих ситуациях, когда надо продублировать одно и то же значение для каждой формируемой строки/столбца.
Вот пример: задача по формированию списка с отдельной строкой на каждую дату этапа.
Вот пример: задача по формированию списка с отдельной строкой на каждую дату этапа.
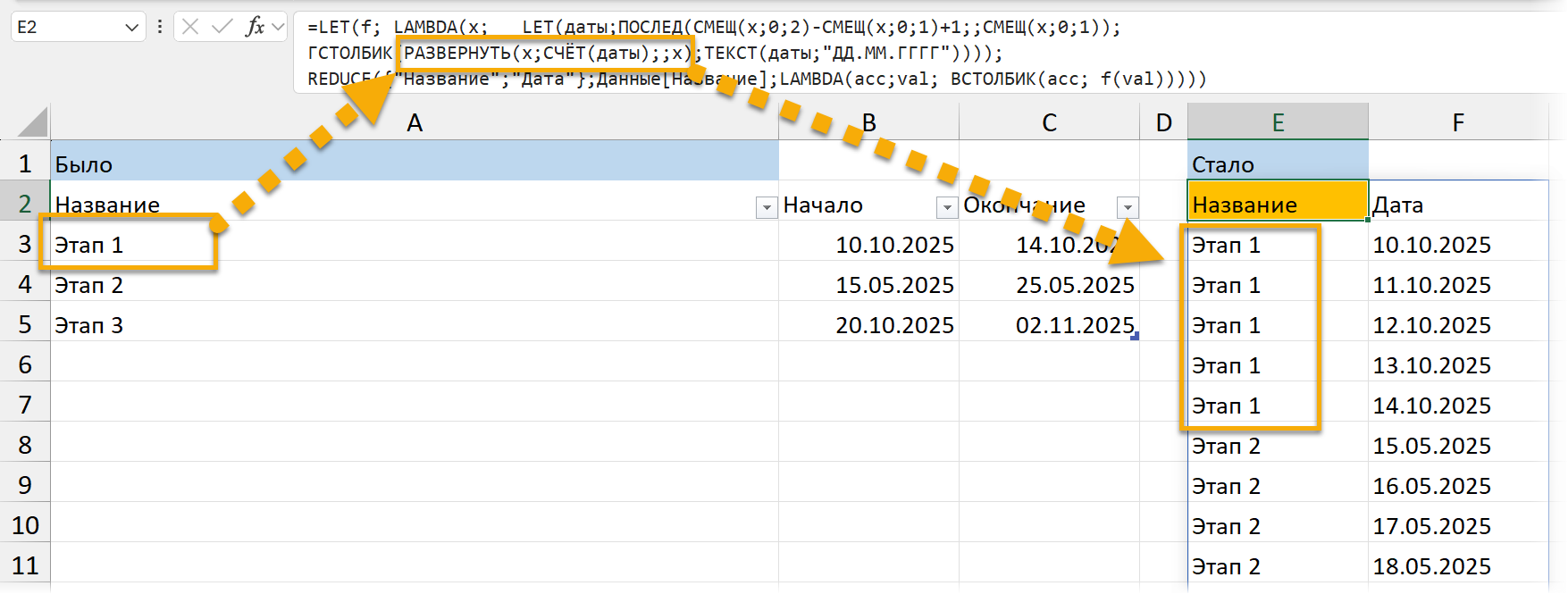
Вкратце про то, что тут вообще происходит:
Мы задаем функцию f.
На входе она получает один параметр — в нашей задаче это название этапа.
И делает следующее:
берет даты на столбец и на два правее от названия этапа (это делает функция СМЕЩ / OFFSET). Тут мы опять пользуемся тем, что переменная работает как ссылка.
Превращает эти даты в последовательность дат от начала и до конца с помощью ПОСЛЕД / SEQUENCE.
Соединяем (ГСТОЛБИК / HSTACK) эти даты с названием этапа, повторенным столько раз, сколько в нем дат. И вот собственно мы повторяем этап с помощью функции EXPAND / РАЗВЕРНУТЬ. Процесс этот на скриншоте выделен оранжевым цветом и стрелками.
Ну, а число дат в последовательности считаем через старый добрый СЧЁТ / COUNT.
И далее эту функцию мы используем. В качестве первоначального аргумента в REDUCE мы отправляем заголовки, а далее накапливаем результат: пробегаемся по списку этапов, для каждого получаем таблицу с помощью написанной нами функции f, и добавляем полученные таблицы одна под другой с помощью ВСТОЛБИК / VSTACK.
Вот ссылка на другой пример с использованием EXPAND при сборе данных из разных таблиц. Там мы добавляем название умной таблицы к каждой строке с собранными из нее данными.
В Google Таблицах такой функции нет, и там можно использовать MAKEARRAY — как раз без использования переменных с номером столбца и строки в формуле, а сугубо формирования списка одинаковых значений ради.
Мы задаем функцию f.
На входе она получает один параметр — в нашей задаче это название этапа.
И делает следующее:
берет даты на столбец и на два правее от названия этапа (это делает функция СМЕЩ / OFFSET). Тут мы опять пользуемся тем, что переменная работает как ссылка.
Превращает эти даты в последовательность дат от начала и до конца с помощью ПОСЛЕД / SEQUENCE.
Соединяем (ГСТОЛБИК / HSTACK) эти даты с названием этапа, повторенным столько раз, сколько в нем дат. И вот собственно мы повторяем этап с помощью функции EXPAND / РАЗВЕРНУТЬ. Процесс этот на скриншоте выделен оранжевым цветом и стрелками.
Ну, а число дат в последовательности считаем через старый добрый СЧЁТ / COUNT.
И далее эту функцию мы используем. В качестве первоначального аргумента в REDUCE мы отправляем заголовки, а далее накапливаем результат: пробегаемся по списку этапов, для каждого получаем таблицу с помощью написанной нами функции f, и добавляем полученные таблицы одна под другой с помощью ВСТОЛБИК / VSTACK.
Вот ссылка на другой пример с использованием EXPAND при сборе данных из разных таблиц. Там мы добавляем название умной таблицы к каждой строке с собранными из нее данными.
В Google Таблицах такой функции нет, и там можно использовать MAKEARRAY — как раз без использования переменных с номером столбца и строки в формуле, а сугубо формирования списка одинаковых значений ради.
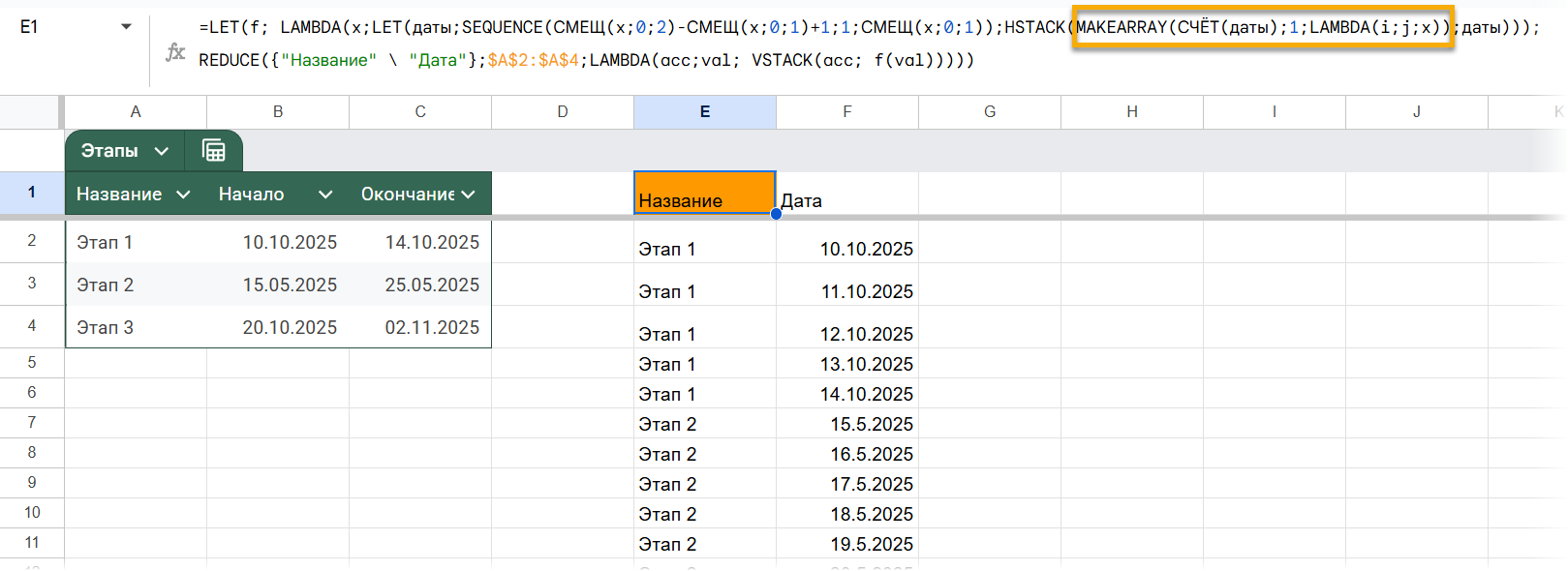
Рекурсия в LAMBDA
Есть такая! Можно функцию вызывать из нее самой. Но в случае с рекурсией важно прописать условие для выхода из бесконечного цикла, иначе формула будет возвращать ошибку.
То есть в общем виде как-то так:
= LAMBDA (переменные; ЕСЛИ (условие; значение_если_истина — то есть выход из цикла; ЭтаФункция (…)))
Попробуем сначала простой вариант — факториал. Создаем вот такую именованную функцию:
=LAMBDA (x; ЕСЛИ (x = 0; 1; x*ФАКТОРИАЛ (x-1)))
И сохраняем ее… под именем ФАКТОРИАЛ, да.
То есть в общем виде как-то так:
= LAMBDA (переменные; ЕСЛИ (условие; значение_если_истина — то есть выход из цикла; ЭтаФункция (…)))
Попробуем сначала простой вариант — факториал. Создаем вот такую именованную функцию:
=LAMBDA (x; ЕСЛИ (x = 0; 1; x*ФАКТОРИАЛ (x-1)))
И сохраняем ее… под именем ФАКТОРИАЛ, да.
Пробуем:

Если ограничения бы не было, функция стала бы возвращать ошибку. А с проверкой через ЕСЛИ мы доходим до нуля и все работает (и также эта проверка сработает, если мы дадим на вход функции ноль сразу — тогда мы ее уже не успеем вызвать из себя самой, а сразу вернем единицу и на этом все).
Обратите внимание на то, что есть ограничение на количество вызовов функцией самой себя. В первой версии LAMBDA было всего 127. Потом 1024.
После лимит был увеличен. И теперь это 16 380. Только вот это число еще нужно поделить на n, где n — это число переменных + 1 + еще единица, если у вас обычная рекурсия, а не хвостовая (когда рекурсивный вызов будет последней операцией).
То есть если у вас переменная в вашей пользовательской функции одна и рекурсия хвостовая, то будет доступно 8190 вызовов, а если две переменных (или одна и обычная рекурсия), то 5460.
Вот таблица сравнения разных функций с одной и несколькими переменными (есть в книге с примерами):
Обратите внимание на то, что есть ограничение на количество вызовов функцией самой себя. В первой версии LAMBDA было всего 127. Потом 1024.
После лимит был увеличен. И теперь это 16 380. Только вот это число еще нужно поделить на n, где n — это число переменных + 1 + еще единица, если у вас обычная рекурсия, а не хвостовая (когда рекурсивный вызов будет последней операцией).
То есть если у вас переменная в вашей пользовательской функции одна и рекурсия хвостовая, то будет доступно 8190 вызовов, а если две переменных (или одна и обычная рекурсия), то 5460.
Вот таблица сравнения разных функций с одной и несколькими переменными (есть в книге с примерами):

Один из классических примеров применения рекурсии — когда вам нужно в разных текстовых строках удалять несколько разных символов или заменять слова на другие слова по списку. Если нужно удалять все символы из ячейки, сработает такая функция:
=LAMBDA (т; символы; ЕСЛИ (символы<>"";
УДАЛИСИМВОЛЫ (ПОДСТАВИТЬ (т; ЛЕВСИМВ (символы;1); "");
ПРАВСИМВ (символы; ДЛСТР (символы) -1)); т))
Ее нужно будет сохранить в диспетчере имен (Ctrl + F3).
Под именем УДАЛИСИМВОЛЫ, как вы уже, вероятно, догадались :)
Здесь т = текст, в котором удаляем.
символы = ячейка с символами для удаления.
Соответственно, если была бы задача заменять, а не удалять, вместо пустой текстовой строки в последнем аргументе функции ПОДСТАВИТЬ / SUBSTITUTE был бы символ или текст, на который нужно заменять (фиксированный или это был бы еще один аргумент нашей функции).
Получается, что мы на каждом шаге берем очередной символ (первый — с помощью функции ЛЕВСИМВ / LEFT из ячейки (в примере ячейки D2) и заменяем его на ничто. Набором символов на удаление становится предыдущий набор за вычетом одного — с помощью ПРАВСИМВ / RIGHT мы берем все символы, кроме первого (количество определяем как число символов в текущем наборе через ДЛСТР / LEN за вычетом единицы).
Эта формула есть в книге Excel с примерами к статье.
=LAMBDA (т; символы; ЕСЛИ (символы<>"";
УДАЛИСИМВОЛЫ (ПОДСТАВИТЬ (т; ЛЕВСИМВ (символы;1); "");
ПРАВСИМВ (символы; ДЛСТР (символы) -1)); т))
Ее нужно будет сохранить в диспетчере имен (Ctrl + F3).
Под именем УДАЛИСИМВОЛЫ, как вы уже, вероятно, догадались :)
Здесь т = текст, в котором удаляем.
символы = ячейка с символами для удаления.
Соответственно, если была бы задача заменять, а не удалять, вместо пустой текстовой строки в последнем аргументе функции ПОДСТАВИТЬ / SUBSTITUTE был бы символ или текст, на который нужно заменять (фиксированный или это был бы еще один аргумент нашей функции).
Получается, что мы на каждом шаге берем очередной символ (первый — с помощью функции ЛЕВСИМВ / LEFT из ячейки (в примере ячейки D2) и заменяем его на ничто. Набором символов на удаление становится предыдущий набор за вычетом одного — с помощью ПРАВСИМВ / RIGHT мы берем все символы, кроме первого (количество определяем как число символов в текущем наборе через ДЛСТР / LEN за вычетом единицы).
Эта формула есть в книге Excel с примерами к статье.

Еще примеры задач, где используются LAMBDA и вспомогательные функции
Тут и те примеры, что использовались для иллюстрации по ходу статьи, и те, которые не упоминались.
- Одной формулой собираем ТОП-N сделок из всех умных таблиц в списке
- Функция SCAN: нарастающий итог — простой, по каждому году/месяцу или с условием
- Выводим в ячейке выбранные в фильтре значения
- Собираем данные с разных листов в Excel и Google Таблицах (список листов — динамический)
- Импорт данных из всех Google Таблиц в списке с помощью формул
- Суммируем с условием только видимые строки в Excel
- Сортируем данные внутри текстовой строки (пост в моем канале «Магия Excel»)
- Считаем количество ответов на форму… формулой (пост)
Заключение: не формулами едиными
Напоследок отмечу, что формулами инструменты Excel не ограничиваются. И хотя новые формулы с LAMBDA (и вообще новые функции, в том числе для манипуляций с массивами, вроде VSTACK, WRAPROWS/WRAPCOLS, TOCOL/TOROW, DROP/TAKE и других) могут делать многое из того, что раньше делали макросы / Power Query, не всегда они будут лучшим решением.
Но если у вас большие объемы данных, а формулы предполагают лютые манипуляции с формированием массивов (MAKEARRAY, например), ссылками на другие столбцы / строки (СМЕЩ / OFFSET), эти самые формулы могут оказаться очень медленными. Так что забывать про другие инструменты Excel — VBA, Power Query, Power Pivot — тоже не стоит.
Но во многих случаях новые формулы будут очень полезны (например, собирать данные с разных листов или разных гуглотаблиц через IMPORTRANGE) и решение будет куда проще (и все в рамках рабочего листа), чем если бы пришлось писать макрос или скрипт.
Но если у вас большие объемы данных, а формулы предполагают лютые манипуляции с формированием массивов (MAKEARRAY, например), ссылками на другие столбцы / строки (СМЕЩ / OFFSET), эти самые формулы могут оказаться очень медленными. Так что забывать про другие инструменты Excel — VBA, Power Query, Power Pivot — тоже не стоит.
Но во многих случаях новые формулы будут очень полезны (например, собирать данные с разных листов или разных гуглотаблиц через IMPORTRANGE) и решение будет куда проще (и все в рамках рабочего листа), чем если бы пришлось писать макрос или скрипт.