




Задача: заполнить пустоты в объединенных ячейках и склеить заголовки
Рассматриваем вот такие данные: в них заголовки в двух строках, да еще и первая — это объединенные ячейки.
Рассматриваем вот такие данные: в них заголовки в двух строках, да еще и первая — это объединенные ячейки.
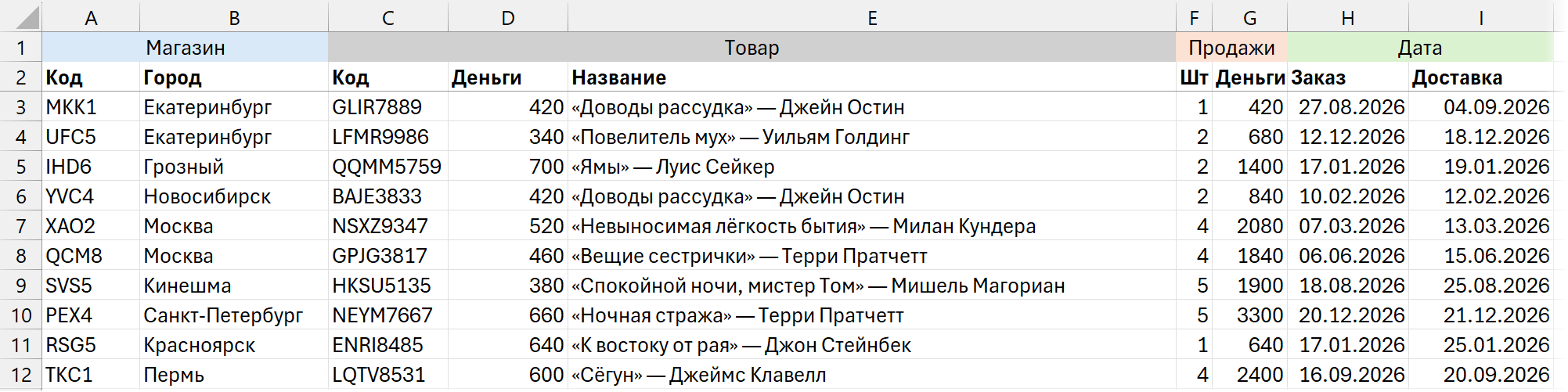
А объединенные ячейки — это, напомню, одна (левая верхняя в объединенном диапазоне) заполненная и все остальные пустые. Это можно увидеть, если сослаться в формуле на первую ячейку и эту формулу потом протянуть:

Хотим заполнить пустые и склеить значения из двух строк, чтобы получить заголовки вида «Магазин | Код», «Товар | Код». Рассмотрим варианты!
Новые формулы в Excel
Начнем с того, что вытащим отдельно строки заголовков — первую и вторую. Ибо делать нам с ними разные вещи — в первой надо заполнять пустые ячейки, а вторую просто приклеить потом к первой с разделителем.
Чтобы извлечь отдельные строки, используем ВЫБОРСТРОК / CHOOSEROWS:
ВЫБОРСТРОК (Данные1;1) — это первая строка.
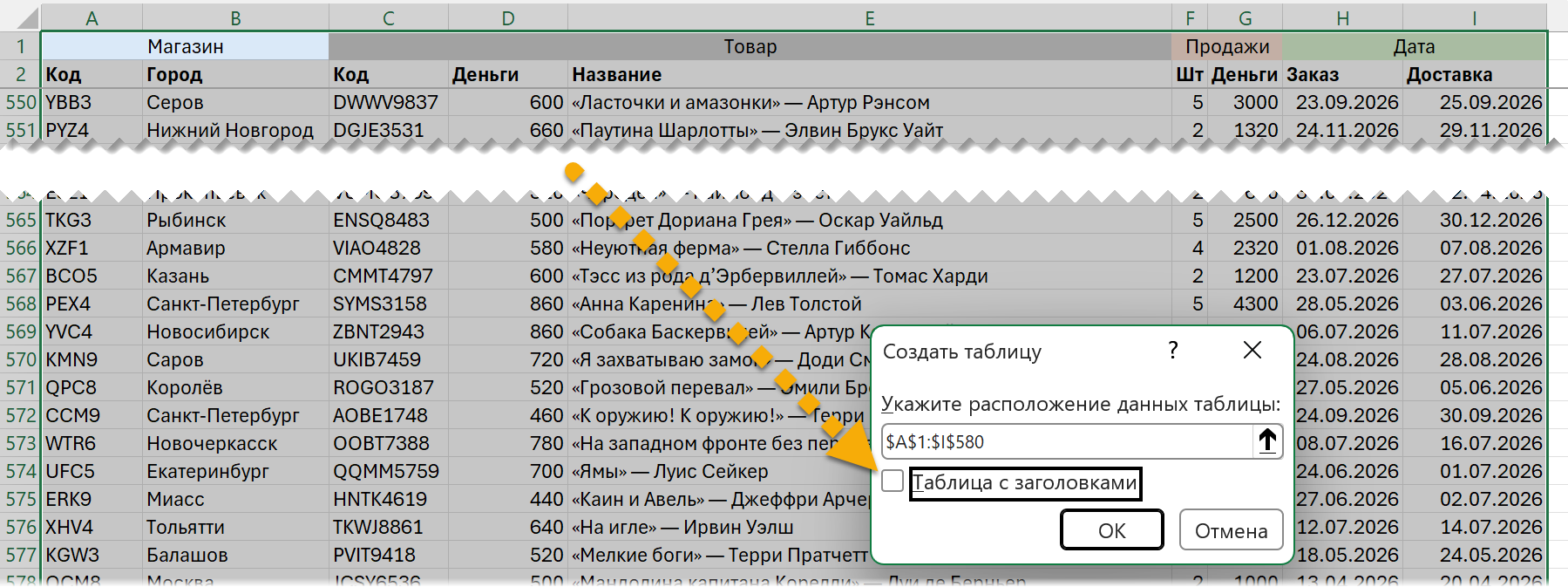
Обратите внимание: для более наглядных формул я сделал диапазон с данными в книге с примерами «умной» таблицей (с именем «Данные1»). Хотя умные таблицы не поддерживают ни объединенные ячейки, ни пустые ячейки в заголовках, второе все-таки возможно, если при создании таблицы (Ctrl + T или Ctrl + L) вы отметите, что заголовков у вас нет. Тогда они будут созданы автоматически с шаблонными именами:
Чтобы извлечь отдельные строки, используем ВЫБОРСТРОК / CHOOSEROWS:
ВЫБОРСТРОК (Данные1;1) — это первая строка.
Обратите внимание: для более наглядных формул я сделал диапазон с данными в книге с примерами «умной» таблицей (с именем «Данные1»). Хотя умные таблицы не поддерживают ни объединенные ячейки, ни пустые ячейки в заголовках, второе все-таки возможно, если при создании таблицы (Ctrl + T или Ctrl + L) вы отметите, что заголовков у вас нет. Тогда они будут созданы автоматически с шаблонными именами:
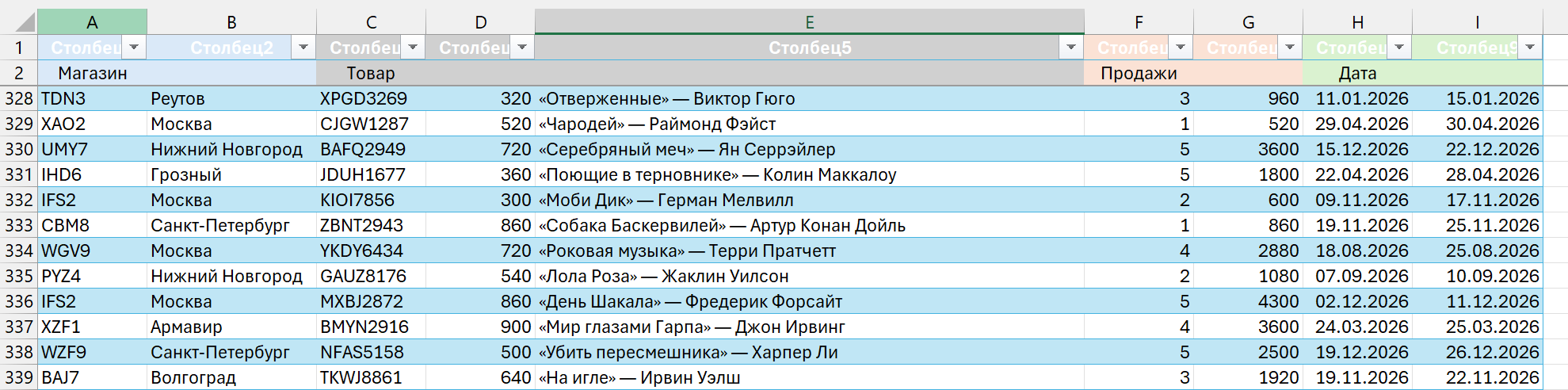
Вот такими:
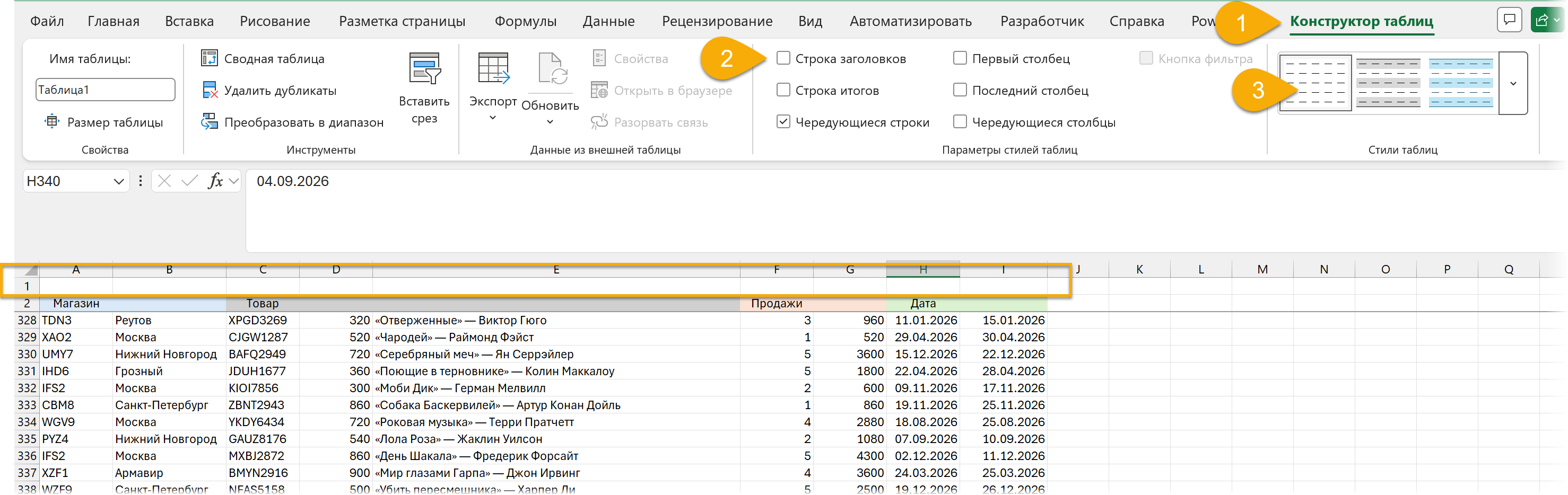
Но их можно убрать на вкладке «Конструктор таблиц» (Table Design) — и заодно там же убрать чередование строк. Тогда внешне это будет не особенно отличаться от обычного диапазона, но это будет именованный объект, и под этим именем будут скрываться все строки таблицы (новые в таблицу попадают автоматически, напомню):
Вернемся к нашей формуле. Вот получили мы первую строку этой таблицы через ВЫБОРСТРОК / CHOOSEROWS, а нам надо по ней пройти и если какое-то значение пустое — заполнить этот элемент массива предыдущим непустым.

Воспользуемся функцией SCAN: начнем с пустоты (пустой текстовой строки), пройдем по массиву, и будем проверять каждое значение на пустоту. Если значение не пустое (проверяем функцией ЕПУСТО / ISBLANK) — возвращаем его. Если пустое — то вместо него возвращаем предыдущее. Подробнее про функцию SCAN можно прочитать в отдельной статье. Вкратце — мы даем начальное значение и массив, а далее обращаемся как к каждому значению этого массива (можно назвать его как удобно, обычно — val, от value — значение) и к предыдущему результату вычисления (обычно acc, accumulator).
=SCAN ("";ВЫБОРСТРОК (Данные1;1); LAMBDA (acc;val; ЕСЛИ (ЕПУСТО (val);acc;val)))
=SCAN ("";ВЫБОРСТРОК (Данные1;1); LAMBDA (acc;val; ЕСЛИ (ЕПУСТО (val);acc;val)))

Еще раз подчеркну: переменные в LAMBDA можно называть как угодно. Важен порядок: первая переменная — это результат предыдущего вычисления, а вторая — текущее значение в массиве (который в SCAN идет во втором аргументе; в нашем примере это функция ВЫБОРСТРОК, то есть первая строка нашей таблицы).
Так что такой вариант будет работать полностью аналогично (конечно, это дикая путаница, так что сугубо в качестве иллюстрации, для понимания):
=SCAN ("";ВЫБОРСТРОК (Данные1;1); LAMBDA (val;acc; ЕСЛИ (ЕПУСТО (acc);val;acc)))
И такой тоже:
=SCAN ("";ВЫБОРСТРОК (Данные1;1); LAMBDA (Кот;Лемур; ЕСЛИ (ЕПУСТО (Лемур);Кот;Лемур)))
Ну, а нам остается к заголовкам первой строки (уже без пропусков) добавить вторую — амперсандом, по желанию — через разделитель:
SCAN (…) &" | "& ВЫБОРСТРОК (Данные1;2)
Так что такой вариант будет работать полностью аналогично (конечно, это дикая путаница, так что сугубо в качестве иллюстрации, для понимания):
=SCAN ("";ВЫБОРСТРОК (Данные1;1); LAMBDA (val;acc; ЕСЛИ (ЕПУСТО (acc);val;acc)))
И такой тоже:
=SCAN ("";ВЫБОРСТРОК (Данные1;1); LAMBDA (Кот;Лемур; ЕСЛИ (ЕПУСТО (Лемур);Кот;Лемур)))
Ну, а нам остается к заголовкам первой строки (уже без пропусков) добавить вторую — амперсандом, по желанию — через разделитель:
SCAN (…) &" | "& ВЫБОРСТРОК (Данные1;2)

Нам остается добавить сюда, к этим сформированным заголовкам, строки с данными из таблицы — все, кроме первых двух строк. Как получить все строки, кроме N? Функция СБРОСИТЬ / DROP — даем ей массив и сколько строк надо сбросить.
=СБРОСИТЬ (Данные1;2)
Ну и соберем вместе наши заголовки (SCAN) и данные (СБРОСИТЬ). Объединить несколько массивов в один вертикально можно функцией ВСТОЛБИК / VSTACK. В общем виде:
=ВСТОЛБИК (Заголовки; Данные)
В менее общем:
=ВСТОЛБИК (…SCAN (ВЫБОРСТРОК (Данные;2)…) & " | "& ВЫБОРСТРОК (Данные;2); СБРОСИТЬ (Данные;2)
И наконец наша формула:
=ВСТОЛБИК (SCAN ("";ВЫБОРСТРОК (Данные1;1);LAMBDA (acc;val;ЕСЛИ (ЕПУСТО (val);acc;val)))&" | "&ВЫБОРСТРОК (Данные1;2); СБРОСИТЬ (Данные1;2))
Одна формула заполняет пустоты, собирает заголовки из двух строк и добавляет снизу остальные данные.
=СБРОСИТЬ (Данные1;2)
Ну и соберем вместе наши заголовки (SCAN) и данные (СБРОСИТЬ). Объединить несколько массивов в один вертикально можно функцией ВСТОЛБИК / VSTACK. В общем виде:
=ВСТОЛБИК (Заголовки; Данные)
В менее общем:
=ВСТОЛБИК (…SCAN (ВЫБОРСТРОК (Данные;2)…) & " | "& ВЫБОРСТРОК (Данные;2); СБРОСИТЬ (Данные;2)
И наконец наша формула:
=ВСТОЛБИК (SCAN ("";ВЫБОРСТРОК (Данные1;1);LAMBDA (acc;val;ЕСЛИ (ЕПУСТО (val);acc;val)))&" | "&ВЫБОРСТРОК (Данные1;2); СБРОСИТЬ (Данные1;2))
Одна формула заполняет пустоты, собирает заголовки из двух строк и добавляет снизу остальные данные.
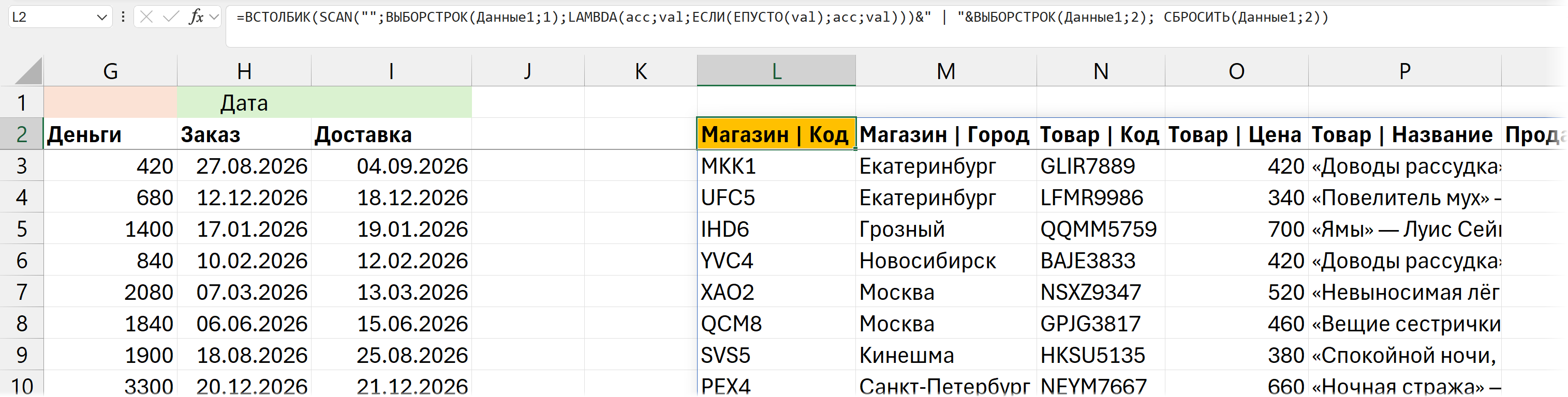
Аналогично все это будет работать и с обычными диапазонами (а не официальной Таблицей) и объединенными / просто пустыми ячейками.
Если будете обращаться к обычным диапазонам, можно сослаться на все строки листа, чтобы предусмотреть появление новых строк с данными (которые в «умную» таблицу попадают автоматически).
=ВСТОЛБИК (SCAN ("";ВЫБОРСТРОК (A:I;1);LAMBDA (acc;val;ЕСЛИ (ЕПУСТО (val);acc;val)))&» | «&ВЫБОРСТРОК (A:I;2); СБРОСИТЬ (A:I;2))
Только вот такая конструкция — со ссылкой на весь миллион с лишним строк (столбцы целиком A: I) будет нещадно тормозить. Так что добавляем точку или функцию УРЕЗДИАПАЗОН / TRIMRANGE, исключая пустые (пока) строки внизу:
=ВСТОЛБИК (SCAN ("";ВЫБОРСТРОК (A:.I;1);LAMBDA (acc;val;ЕСЛИ (ЕПУСТО (val);acc;val)))&» | «&ВЫБОРСТРОК (A:.I;2); СБРОСИТЬ (A:.I;2))
Можно задать переменную для этого диапазона A:.I и использовать ее:
=LET (data;A:.I;
ВСТОЛБИК (SCAN ("";ВЫБОРСТРОК (data;1);LAMBDA (acc;val;ЕСЛИ (ЕПУСТО (val);acc;val)))&» | «&ВЫБОРСТРОК (data;2);СБРОСИТЬ (data;2)))
Если будете обращаться к обычным диапазонам, можно сослаться на все строки листа, чтобы предусмотреть появление новых строк с данными (которые в «умную» таблицу попадают автоматически).
=ВСТОЛБИК (SCAN ("";ВЫБОРСТРОК (A:I;1);LAMBDA (acc;val;ЕСЛИ (ЕПУСТО (val);acc;val)))&» | «&ВЫБОРСТРОК (A:I;2); СБРОСИТЬ (A:I;2))
Только вот такая конструкция — со ссылкой на весь миллион с лишним строк (столбцы целиком A: I) будет нещадно тормозить. Так что добавляем точку или функцию УРЕЗДИАПАЗОН / TRIMRANGE, исключая пустые (пока) строки внизу:
=ВСТОЛБИК (SCAN ("";ВЫБОРСТРОК (A:.I;1);LAMBDA (acc;val;ЕСЛИ (ЕПУСТО (val);acc;val)))&» | «&ВЫБОРСТРОК (A:.I;2); СБРОСИТЬ (A:.I;2))
Можно задать переменную для этого диапазона A:.I и использовать ее:
=LET (data;A:.I;
ВСТОЛБИК (SCAN ("";ВЫБОРСТРОК (data;1);LAMBDA (acc;val;ЕСЛИ (ЕПУСТО (val);acc;val)))&» | «&ВЫБОРСТРОК (data;2);СБРОСИТЬ (data;2)))
Power Query в Excel
Давайте загрузим таблицу в Power Query и попробуем обработать там.
Данные — Получить данные — Из таблицы / диапазона:
Данные — Получить данные — Из таблицы / диапазона:
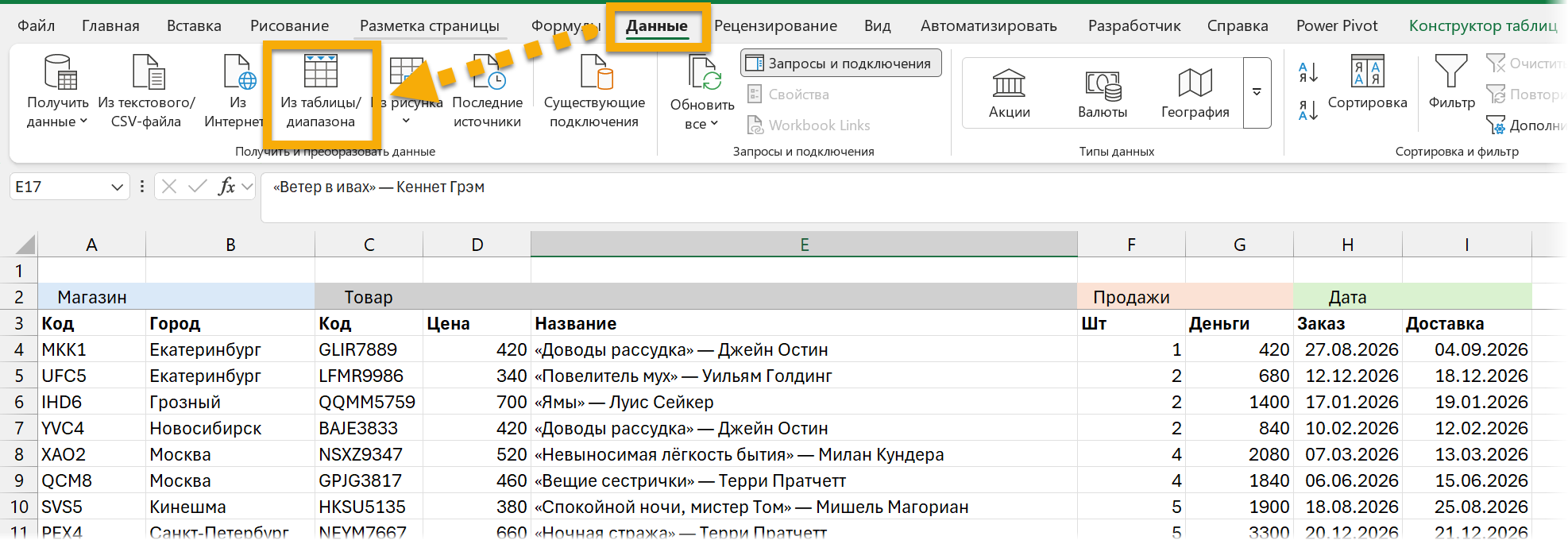
Там автоматически повысятся заголовки из первой строки (функция Table. PromoteHeaders и шаг «Повышенные заголовки») — но нам это не подходит, часть ячеек пуста и в этих столбцах будут заголовки вида «ColumnN», к тому же нам еще нужна вторая строка. Так что удаляем этот шаг, нажимая на крестик рядом с ним в списке шагов.

После удаления шага будет такая картинка:
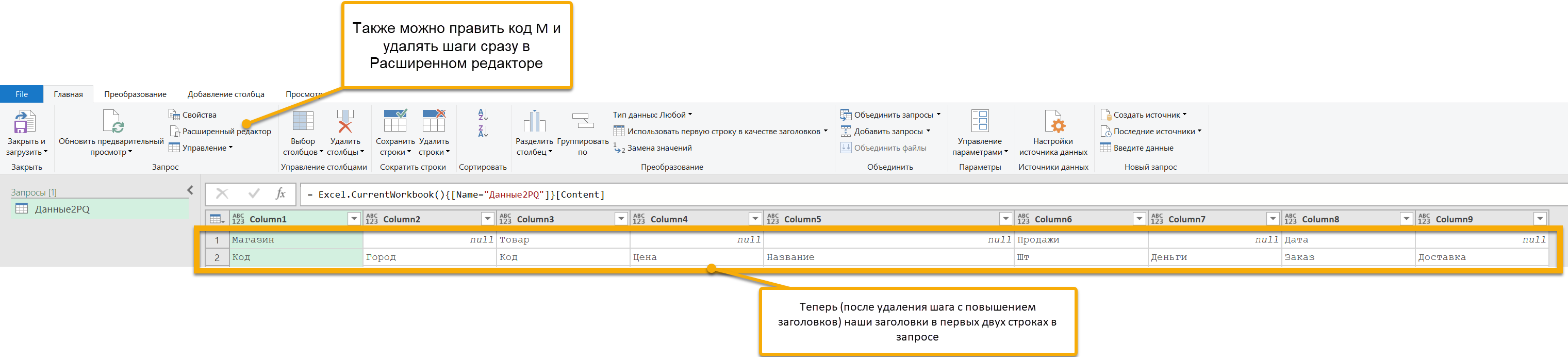
Мы зайдем в Расширенный редактор, чтобы сразу писать код запроса там. И введем функцию Table.SplitAt, которой в качестве таблицы дадим наш первый шаг, то есть исходную таблицу с листа Excel, а в качестве второго аргумента — 2. И получим список из двух таблиц, разделенных после второй строки. В первой будут наши заголовки:
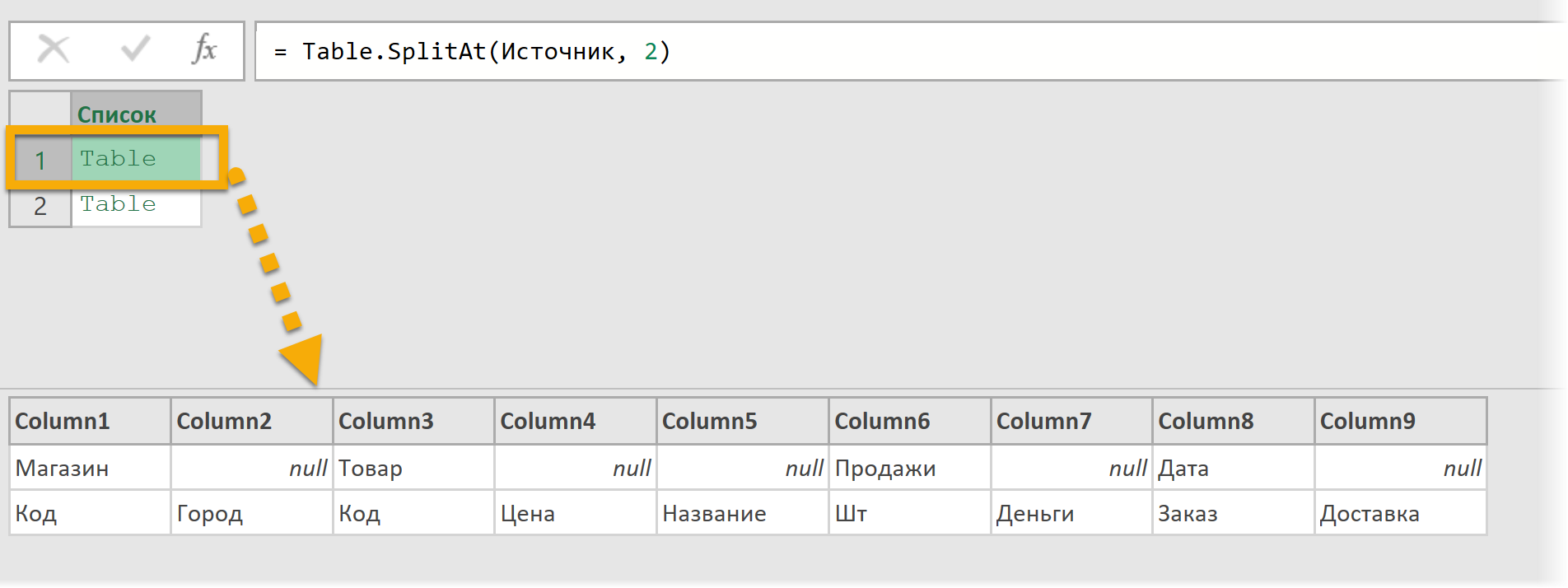
Во второй остальные данные:
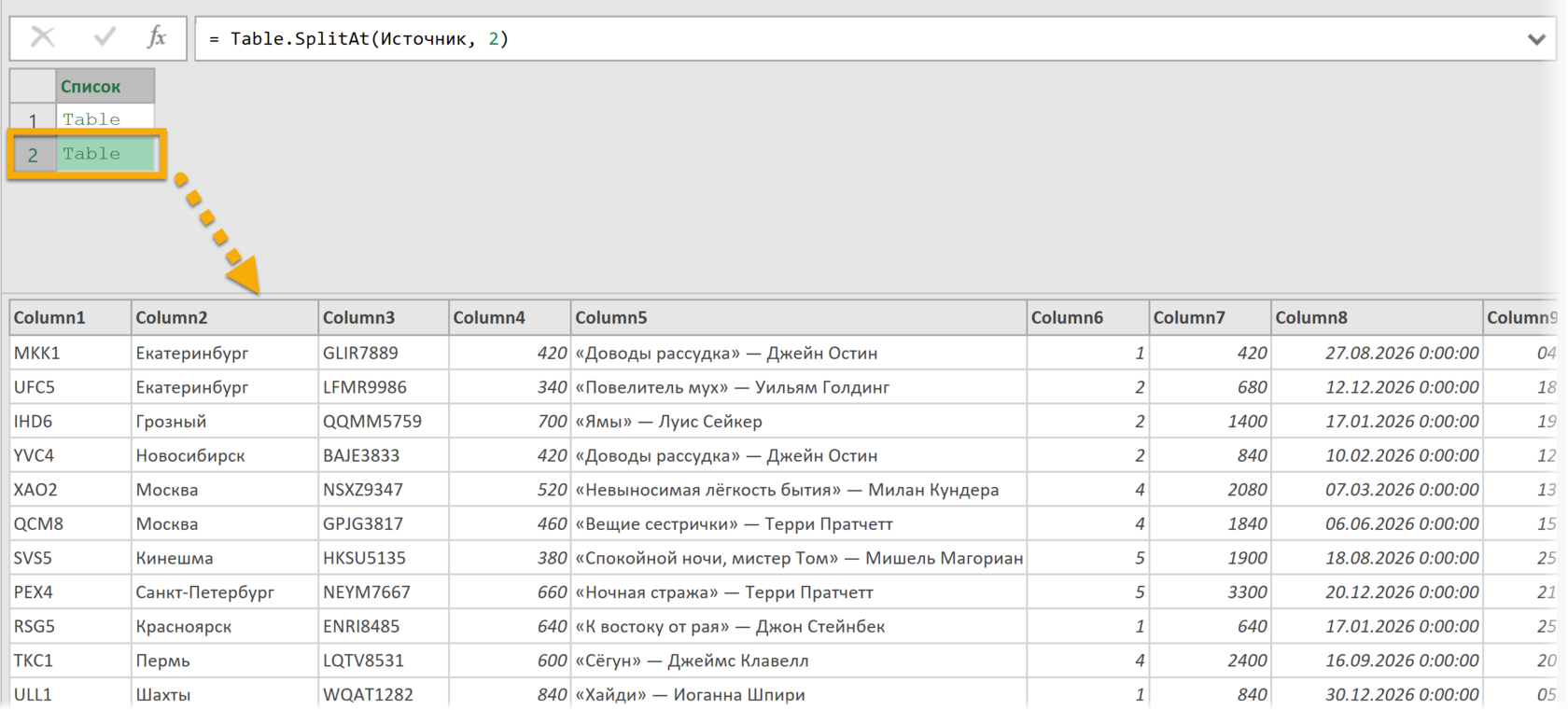
Чтобы посмотреть на содержимое таблицы (как на двух скриншотах выше), находящейся в ячейке, кликайте не по самой надписи Table, а по белому пространству рядом в ячейке с ней.
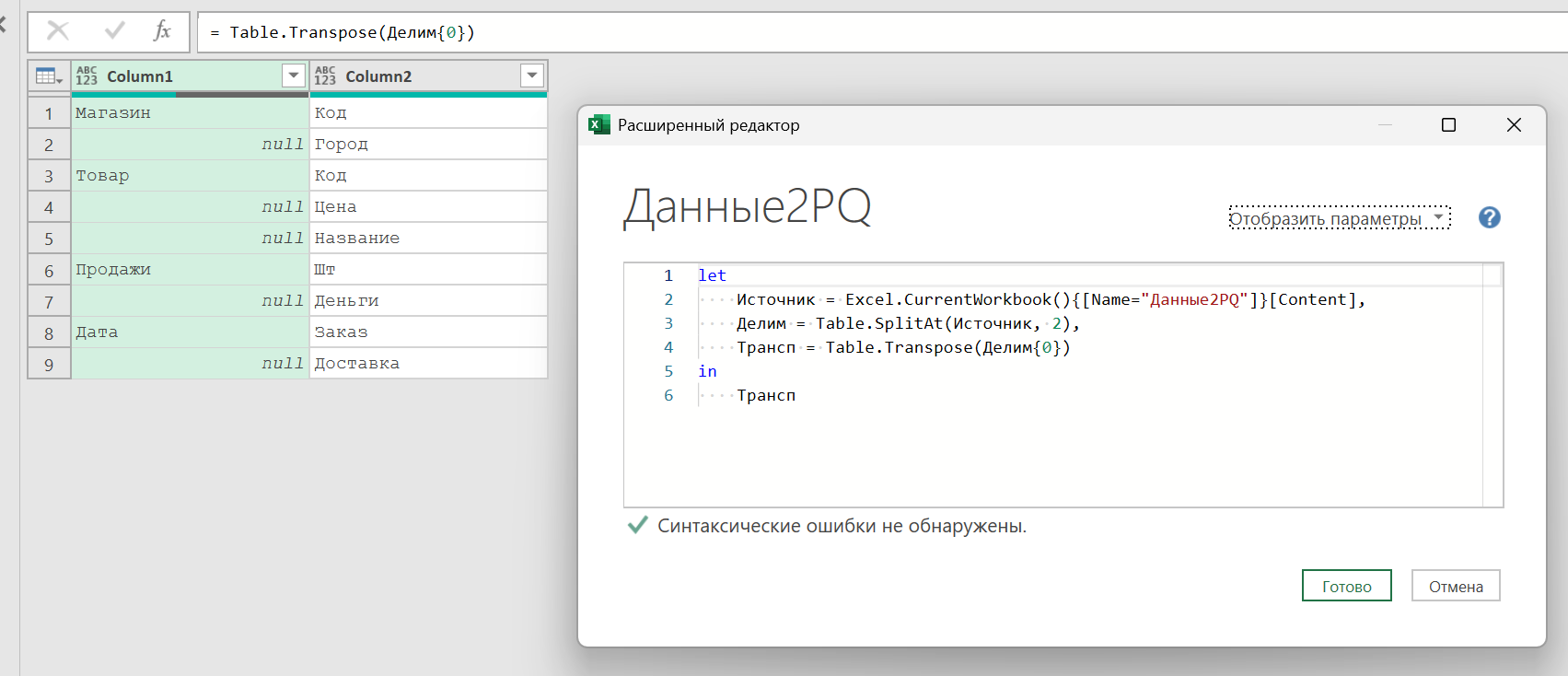
Далее нам надо заполнить пустоты в первой строке первой таблицы. Для этого в Power Query есть «Заполнить вниз» (функция Table.FillDown), но у нас не вниз, а вбок. Так что сначала надо будет транспонировать таблицу (Table.Transpose). Нам нужно сделать это только с первой таблицей из двух. К элементу списка можно обращаться по его номеру в фигурных скобках, не забывая про то, что в PQ нумерация с нуля:
НазваниеШагаСоСписком{0} — первый элемент списка с предыдущего шага, то есть первая таблица. Ее транспонируем:
Далее нам надо заполнить пустоты в первой строке первой таблицы. Для этого в Power Query есть «Заполнить вниз» (функция Table.FillDown), но у нас не вниз, а вбок. Так что сначала надо будет транспонировать таблицу (Table.Transpose). Нам нужно сделать это только с первой таблицей из двух. К элементу списка можно обращаться по его номеру в фигурных скобках, не забывая про то, что в PQ нумерация с нуля:
НазваниеШагаСоСписком{0} — первый элемент списка с предыдущего шага, то есть первая таблица. Ее транспонируем:
Теперь заполним вниз:
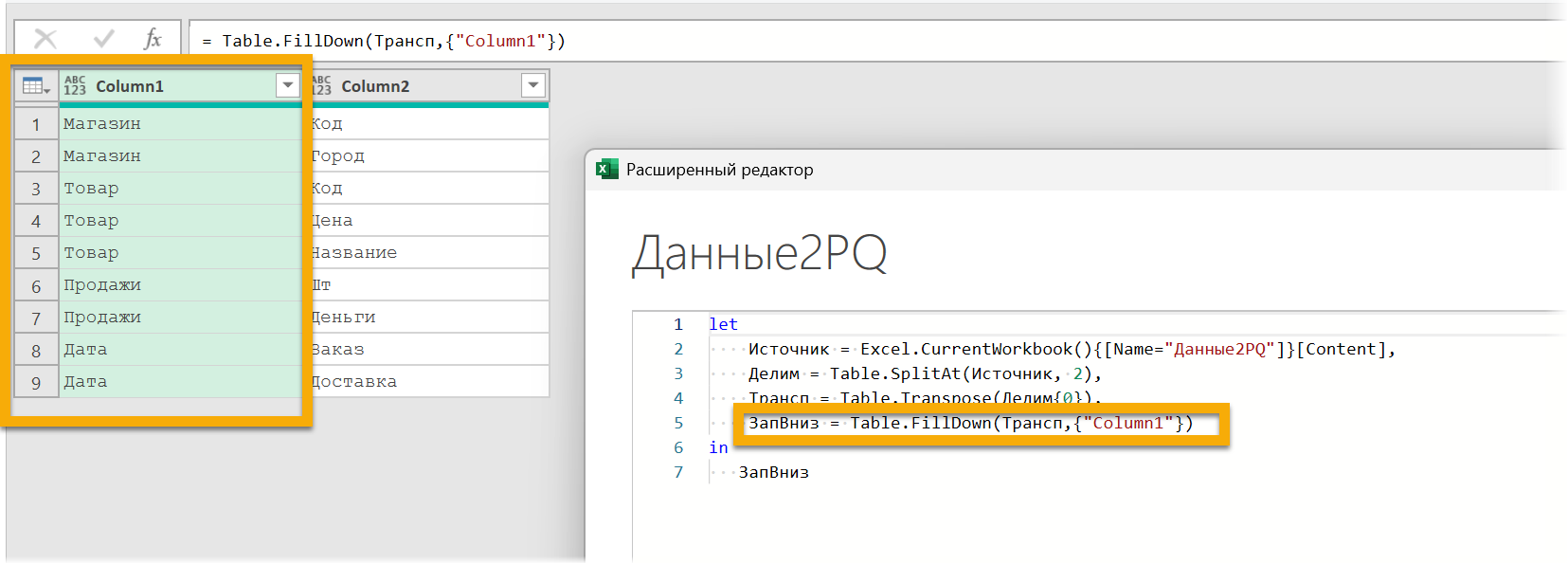
Второй аргумент функции Table.FillDown — список столбцов, которые мы заполняем. У меня имя столбца жестко вшито в функцию как «Column1», здесь это допустимо, ведь мы не используем заголовки, которые есть у нас в данных, мы убрали шаг с повышением заголовков. Так что у нас в любом случае названия столбцов по умолчанию.
Если нужно получить все имена таблицы, мы бы написали вместо одного имени функцию Table.ColumnNames (Трансп).
А если нужно имя только первого столбца — можно получить его через List.Range с отступом 0 (первый аргумент) и третьим аргументом, равным единице — то есть берем один первый элемент:
List.Range (Table.ColumnNames (Трансп), 0,1).
Теперь объединяем эти два столбца функцией Table.CombineColumns. Даем ей список всех столбцов — можно было вручную {"Column1", «Column2"}, можно получить функцией Table.ColumnNames. Функция для объединения — Combiner. CombineTextByDelimiter с аргументом в виде текстовой строки, выступающей разделителем. У нас это будет вертикальная черта с пробелами. Последний аргумет функции — название нового столбца:
Table.CombineColumns (Table.FillDown (Трансп,{"Column1"}), Table. ColumnNames (Трансп), Combiner. CombineTextByDelimiter (" | "),"Заголовки»)
Если нужно получить все имена таблицы, мы бы написали вместо одного имени функцию Table.ColumnNames (Трансп).
А если нужно имя только первого столбца — можно получить его через List.Range с отступом 0 (первый аргумент) и третьим аргументом, равным единице — то есть берем один первый элемент:
List.Range (Table.ColumnNames (Трансп), 0,1).
Теперь объединяем эти два столбца функцией Table.CombineColumns. Даем ей список всех столбцов — можно было вручную {"Column1", «Column2"}, можно получить функцией Table.ColumnNames. Функция для объединения — Combiner. CombineTextByDelimiter с аргументом в виде текстовой строки, выступающей разделителем. У нас это будет вертикальная черта с пробелами. Последний аргумет функции — название нового столбца:
Table.CombineColumns (Table.FillDown (Трансп,{"Column1"}), Table. ColumnNames (Трансп), Combiner. CombineTextByDelimiter (" | "),"Заголовки»)
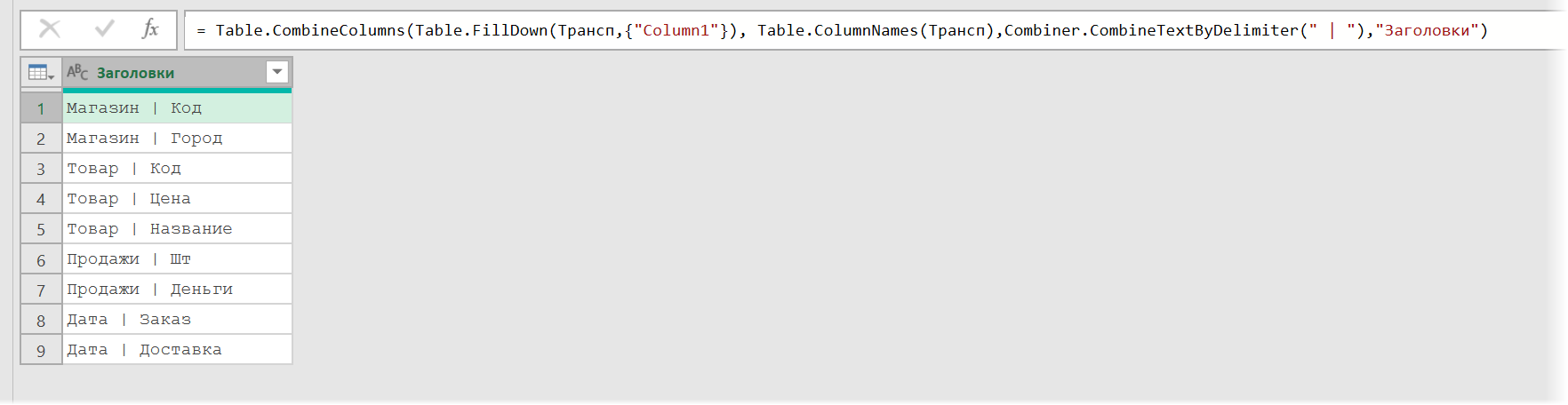
Остается это дело обратно транспонировать, добавив сверху функцию Table.Transpose.

Дальше объединяем две таблицы амперсандом — таблицу из одной строки с заголовками (шаг «Заголовки») и вторую таблицу с шага «Делим», когда мы разделили по второй строке — это все данные из исходника, кроме двух строк заголовков.
Получаем почти результат, только вот заголовки в первой строке, а не в шапке.
Получаем почти результат, только вот заголовки в первой строке, а не в шапке.
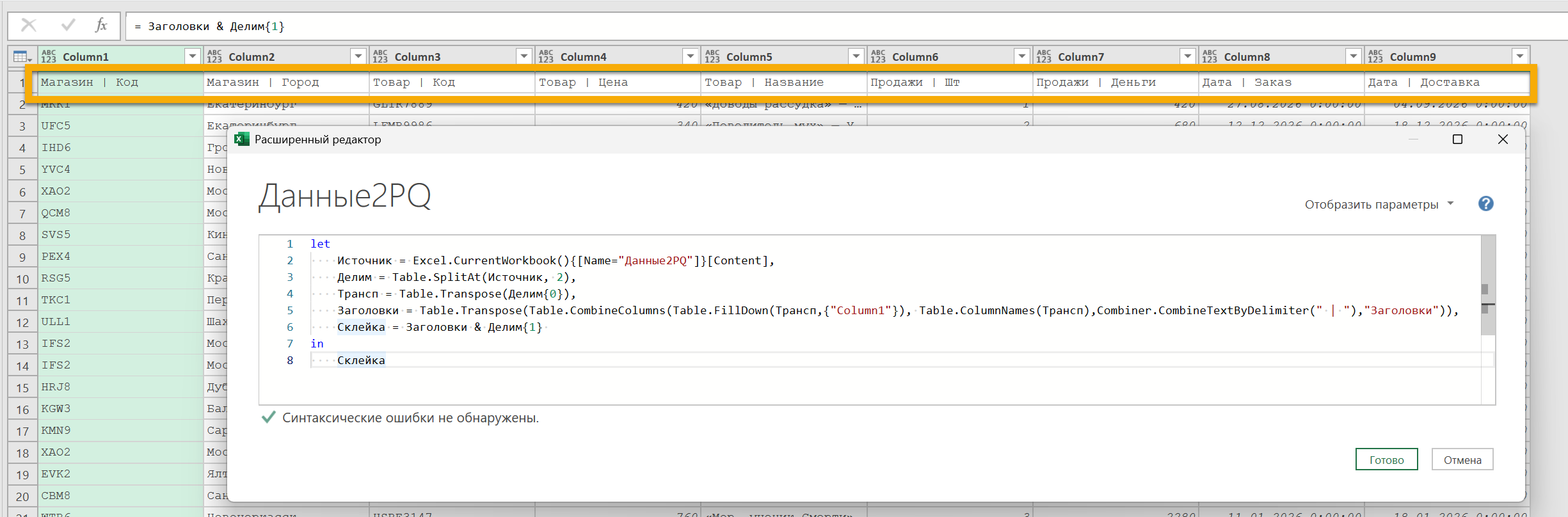
Так что надо добавить функцию Table.PromoteHeaders, которую (созданную автоматически в начале) мы удаляли до всех преобразований.

Все, можно отправлять в Excel в виде таблицы / сводной и/или в модель данных — «Закрыть и загрузить в…»
Как в формулах, так и в Power Query у каждой задачи есть, как правило, несколько решений.
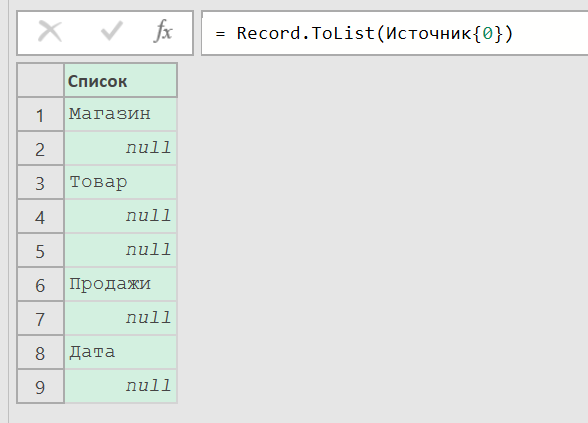
Здесь тоже можно пойти другими путями. Например, не делить таблицу на две, а получить списки из первой и второй строки. Чтобы получить строку таблицы, мы указываем ее индекс (НазваниеТаблицы{0}, например - это первая строка из таблицы "НазваниеТаблицы"), но только тогда мы получим запись с полями, а нам для дальнейших манипуляций лучше преобразовать ее в список - это функция Record.ToList:
Заголовки = Record.ToList(Источник{0})
Здесь тоже можно пойти другими путями. Например, не делить таблицу на две, а получить списки из первой и второй строки. Чтобы получить строку таблицы, мы указываем ее индекс (НазваниеТаблицы{0}, например - это первая строка из таблицы "НазваниеТаблицы"), но только тогда мы получим запись с полями, а нам для дальнейших манипуляций лучше преобразовать ее в список - это функция Record.ToList:
Заголовки = Record.ToList(Источник{0})
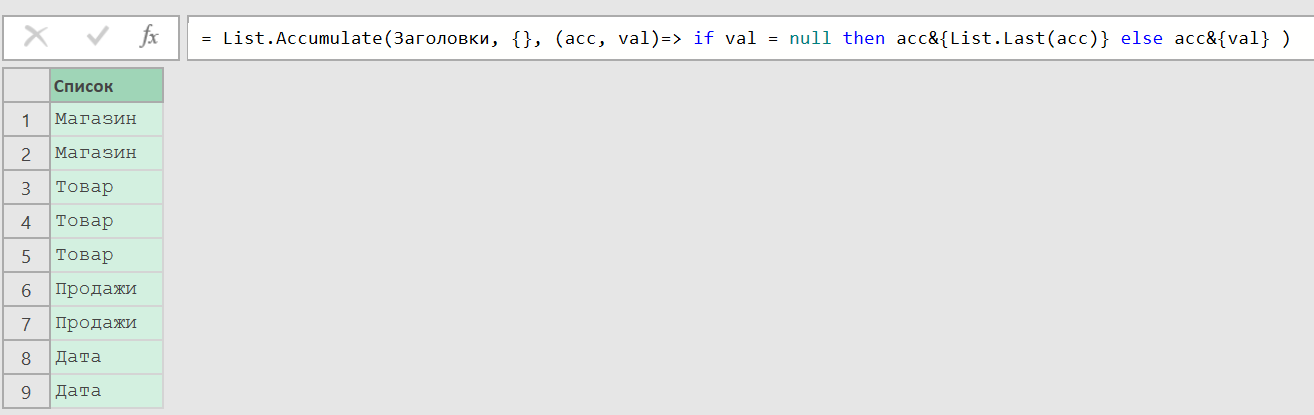
И заполнить значения, например, функцией List.Accumulate. Она похожа на функцию рабочего листа SCAN, которую мы использовали выше. Только работаем мы со списком, а не массивом. Переменных внутри в пользовательской функции тоже две - называть их тоже можно как угодно, важен порядок (первым результат предыдущего вычисления, а вторым текущий элемент списка, который мы дали на вход). Я назову для примера так же, как делал в SCAN - acc и val.
= List.Accumulate(Заголовки, {}, (acc, val)=> if val = null then acc&{List.Last(acc)} else acc&{val} )
Берем список заголовков с предыдущего шага (см предыдущий скриншот), начинаем с пустого списка {}, проверяем значение - если оно пустое (null в Power Query), то добавляем к уже сформированному списку acc последнее значение из него (List.Last), а иначе само текущее значение, очередной элемент списка. На первом шаге к пустому списку мы добавим "Магазин", ибо это val и оно не пустое. На втором val - пустое значение, а acc - список из "Магазина", вот мы и добавим к "Магазину" последнее значение из уже сформированного списка, то есть повторим "Магазин".
= List.Accumulate(Заголовки, {}, (acc, val)=> if val = null then acc&{List.Last(acc)} else acc&{val} )
Берем список заголовков с предыдущего шага (см предыдущий скриншот), начинаем с пустого списка {}, проверяем значение - если оно пустое (null в Power Query), то добавляем к уже сформированному списку acc последнее значение из него (List.Last), а иначе само текущее значение, очередной элемент списка. На первом шаге к пустому списку мы добавим "Магазин", ибо это val и оно не пустое. На втором val - пустое значение, а acc - список из "Магазина", вот мы и добавим к "Магазину" последнее значение из уже сформированного списка, то есть повторим "Магазин".
Потом надо попарно склеить поолученные значения с другой строкой заголовков, где пропусков не было. Эту строку мы получим по той же схеме - получим строку таблицы, превратим в список:
Record.ToList(Источник{1})
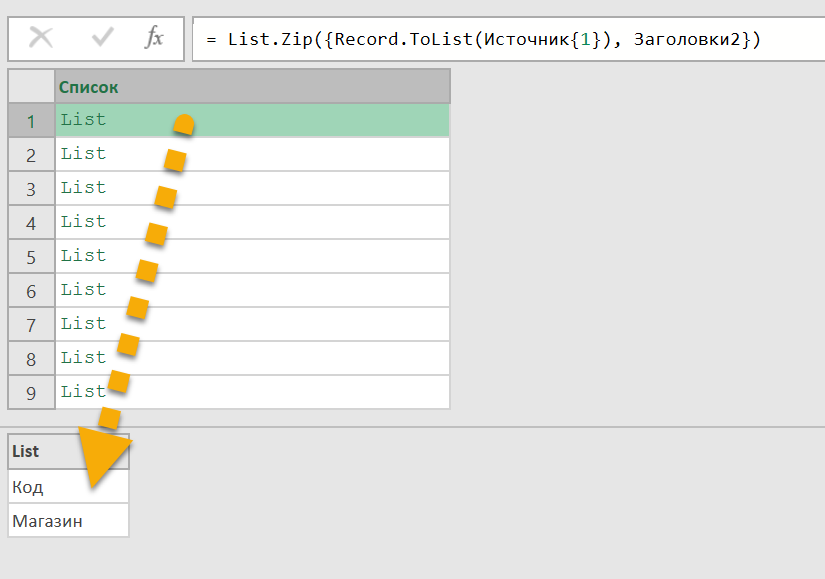
Соберем списки из пар значений, применив функцию List.Zip к двум нашим строкам заголовков:
Record.ToList(Источник{1})
Соберем списки из пар значений, применив функцию List.Zip к двум нашим строкам заголовков:
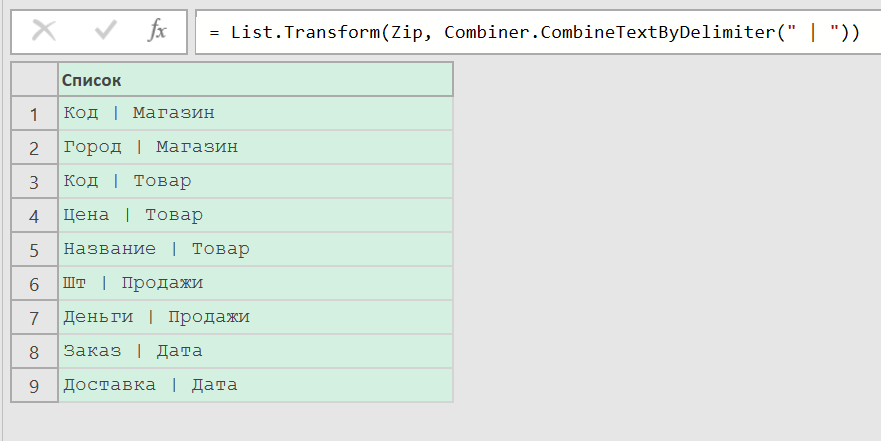
Теперь пройдемся по этим спискам из двух значений и каждый объединим с разделителем:
Теперь нужно переименовать столбцы в исходной таблице на эти и убрать первые две строки оттуда, так как они уже больше не нужны. Убрать столбцы можно функцией Table.Skip - то есть таблица без первых двух строк будет получена так:
Table.Skip(Источник,2)
А переименовать столбцы можно функцией Table.RenameColumns. Ей нужен список переименований. Каждое переименование - это список из двух значений - что и на что меняем. Например, если вам нужно поменять заголовки таблицы "Кот" и "Собака" на "Лемур" и "Штрудель", то список переименований будет таким:
{ {"Кот", "Лемур"}, {"Собака", "Штрудель"} }
Но у нас столбцов много, так что не будем перечислять все руками, конечно, иначе и не было бы смысла формировать список из объединенных значений. Соберем списки для переименований с помощью List.Zip - дадим ей список старых названий (Table.ColumnNames(Источник)) и новых (шаг с именем Заголовки3, результат которого на предыдущем скриншоте).
= List.Zip({Table.ColumnNames(Источник),Заголовки3})
Все вместе будет выглядеть так:
= Table.RenameColumns(Table.Skip(Источник,2), List.Zip({Table.ColumnNames(Источник),Заголовки3}))
Table.Skip(Источник,2)
А переименовать столбцы можно функцией Table.RenameColumns. Ей нужен список переименований. Каждое переименование - это список из двух значений - что и на что меняем. Например, если вам нужно поменять заголовки таблицы "Кот" и "Собака" на "Лемур" и "Штрудель", то список переименований будет таким:
{ {"Кот", "Лемур"}, {"Собака", "Штрудель"} }
Но у нас столбцов много, так что не будем перечислять все руками, конечно, иначе и не было бы смысла формировать список из объединенных значений. Соберем списки для переименований с помощью List.Zip - дадим ей список старых названий (Table.ColumnNames(Источник)) и новых (шаг с именем Заголовки3, результат которого на предыдущем скриншоте).
= List.Zip({Table.ColumnNames(Источник),Заголовки3})
Все вместе будет выглядеть так:
= Table.RenameColumns(Table.Skip(Источник,2), List.Zip({Table.ColumnNames(Источник),Заголовки3}))
Формулы в Google Таблицах
В Google Таблицах есть новые функции — и CHOOSEROWS, и LAMBDA со SCAN'ом, и LET, и VSTACK. Названия у них будут на английском даже при русском языке формул в вашей гуглотаблице.
Так что тоже можно использовать их. Правда, нет функции СБРОСИТЬ / DROP (во всяком случае, на момент написания статьи в 2026 году).
Зато есть функция QUERY! У нее есть третий аргумент «Заголовки», и если там будет число больше единицы, то она «склеит» заголовки из нескольких строк. А уже все остальные данные из массива / диапазона, переданного ей в первом аргументе, она будет считать данными, а не заголовками, и осуществит с ними манипуляции, заданные нами во втором аргументе (подробнее про функцию можно прочитать здесь).
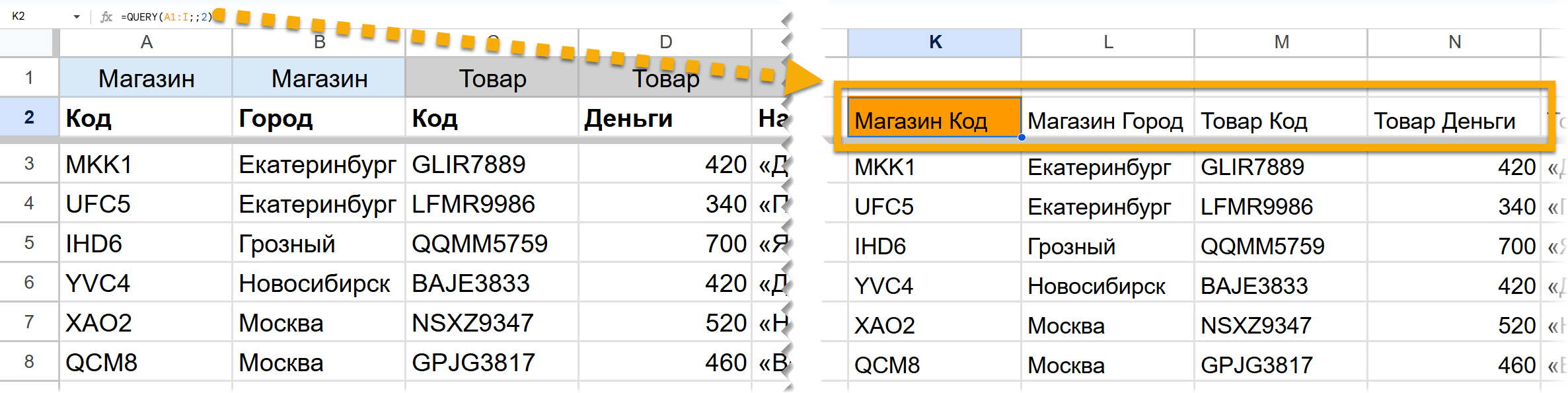
Вот простой пример, где пока еще нет пустот и объединенных ячеек, просто две строки заголовков с заполненными данными — объединим их с помощью QUERY. С данными ничего делать не будем, так что запрос оставим пустым.
=QUERY (A1:I;;2)
Так что тоже можно использовать их. Правда, нет функции СБРОСИТЬ / DROP (во всяком случае, на момент написания статьи в 2026 году).
Зато есть функция QUERY! У нее есть третий аргумент «Заголовки», и если там будет число больше единицы, то она «склеит» заголовки из нескольких строк. А уже все остальные данные из массива / диапазона, переданного ей в первом аргументе, она будет считать данными, а не заголовками, и осуществит с ними манипуляции, заданные нами во втором аргументе (подробнее про функцию можно прочитать здесь).
Вот простой пример, где пока еще нет пустот и объединенных ячеек, просто две строки заголовков с заполненными данными — объединим их с помощью QUERY. С данными ничего делать не будем, так что запрос оставим пустым.
=QUERY (A1:I;;2)
Соответственно, в случае с пустыми ячейками мы их сначала заполним с помощью SCAN, как и в Excel, а уже потом к полученной первой строке добавим вторую — можно сразу вместе с данными. Все это станет первым аргументом QUERY, которую мы попросим рассматривать две строки этого массива в качестве заголовков:
=QUERY (VSTACK (
SCAN ("";A1:I1;LAMBDA (acc;val;ЕСЛИ (ЕПУСТО (val);acc;val)));
A2: I);
"";2)
=QUERY (VSTACK (
SCAN ("";A1:I1;LAMBDA (acc;val;ЕСЛИ (ЕПУСТО (val);acc;val)));
A2: I);
"";2)




